Три месяца назад я переписал весь бэкенд на Bun и Hono. Это решение изменило то, как я думаю о каждом техническом выборе.
Раньше я был тем парнем, который сначала npm install, а потом вопросы. Нужна авторизация? Auth0. Нужна аналитика? Metabase. Нужна observability для LLM? LangSmith. Так ведь положено. Не изобретай велосипед. Строй на плечах гигантов.
А потом я увидел, как AI-агент пишет 500 строк идеального кода для observability за 90 секунд. И всё изменилось.
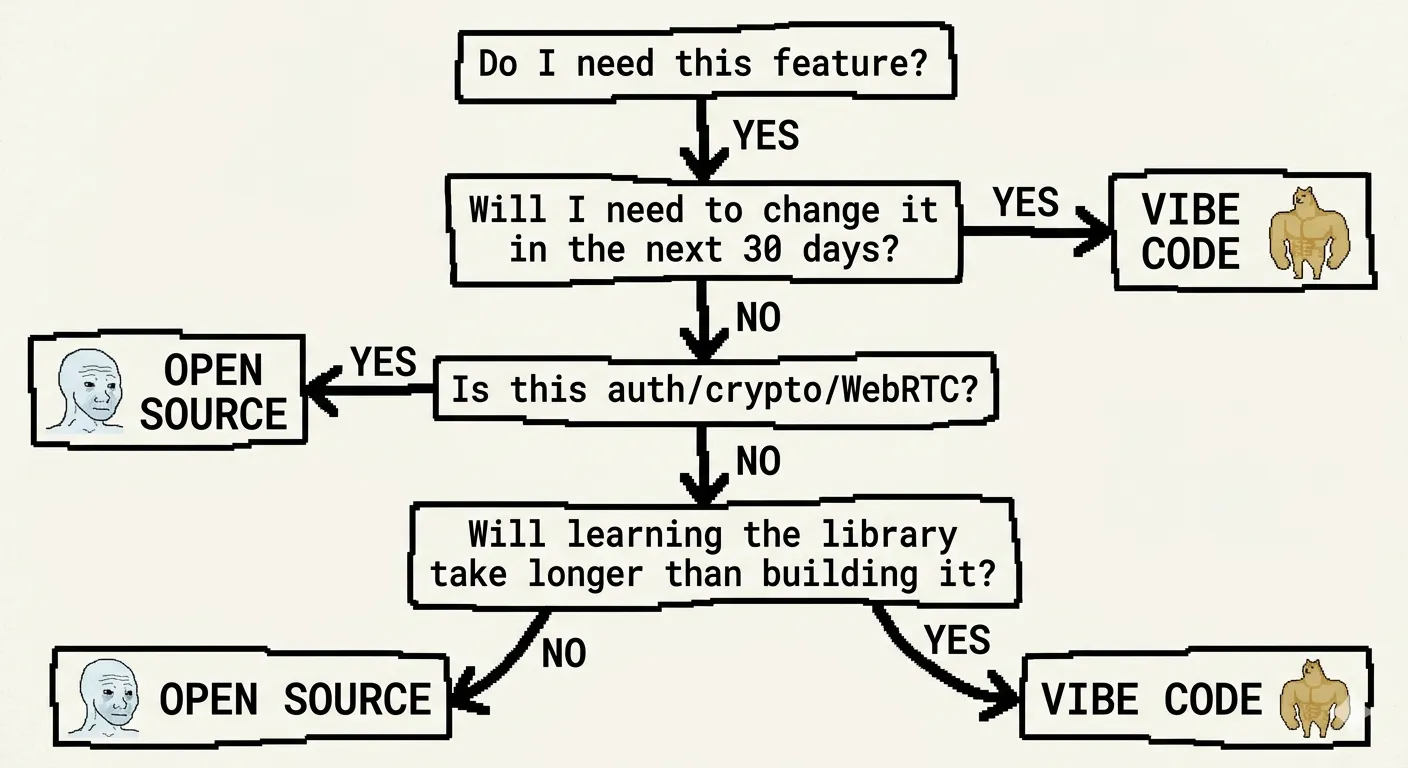
“Вопрос уже не ‘использовать open source или написать самому’. Вопрос — ‘смогу ли я написать это быстрее, чем изучить библиотеку’.”
Это не про упрямство. Это не про синдром NIH. Это про математику. И математика изменилась.
Я разработал простой фреймворк для принятия таких решений. Он не идеален, но работает. И он сэкономил мне недели фрустрации.
Глубокий разбор реализации
Кейс 0: Аутентификация
Это простой случай. Никогда не делай vibe-кодинг для авторизации. Никогда.
Каждый, кто думает “да напишу я простую систему входа”, потом об этом жалеет. Сброс пароля. Верификация email. MFA. Ротация сессий. Rate limiting. Есть 47 граничных случаев, которые ты забудешь, и один из них тебя взломает.
Auth0, Supabase Auth, Firebase, Keycloak — ни одна не идеальна. Все они когда-нибудь тебя разочаруют. Но все они всё равно бесконечно лучше, чем то, что ты напишешь за полдня.
Это не подлежит обсуждению. Некоторые велосипеды не изобретаются.
💡 Инсайт: Аутентификация — единственная категория, где цена ошибки катастрофическая. Никакая экономия времени не стоит того, чтобы подвергать данные пользователей риску.
Кейс 1: Омниканальный inbox
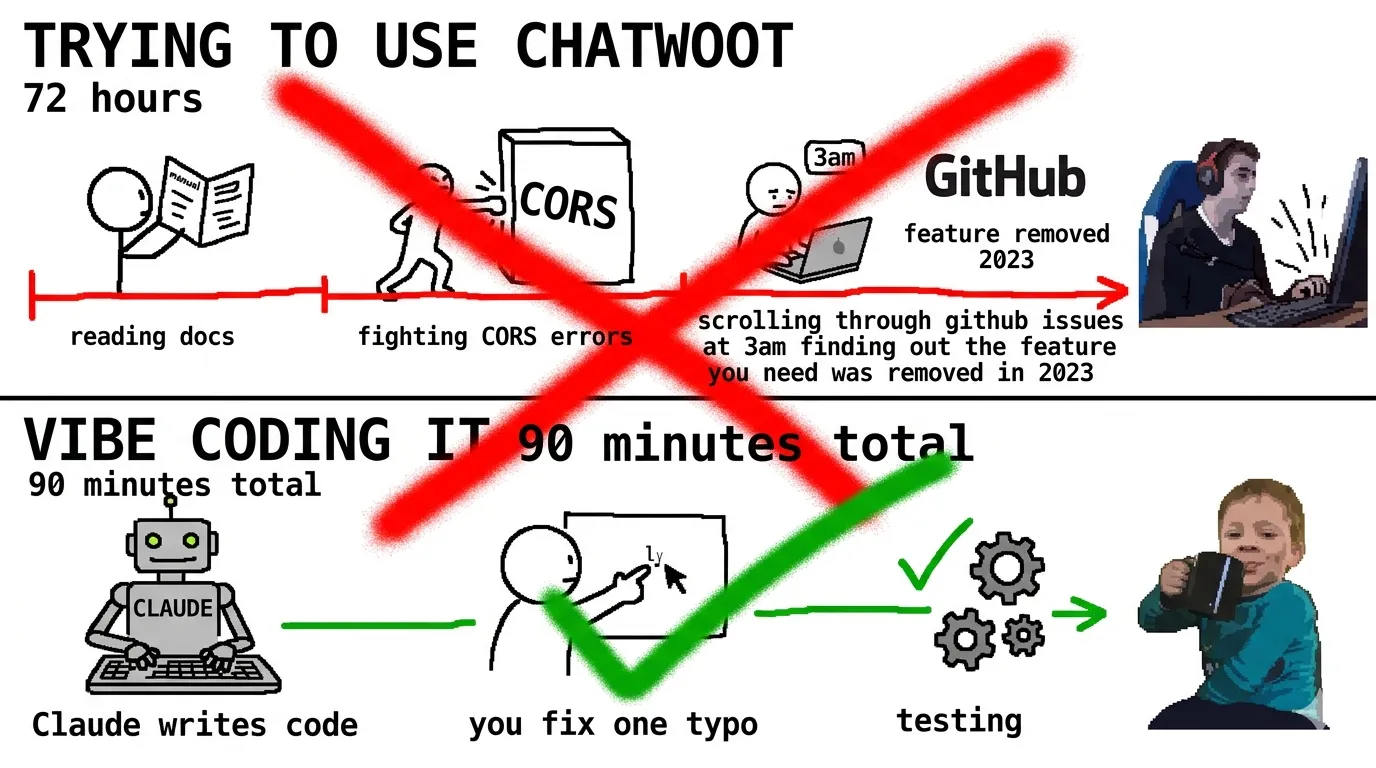
Я использовал Chatwoot в прошлой компании. Он хороший. Документация нормальная. Стабильный. Довольно быстрый. Я бы рекомендовал его 90% людей.
Но Chatwoot создан для живых агентов. Я строю для AI.
Мне не нужны правила распределения. Мне не нужны командные inbox-ы. Мне не нужны таймеры SLA. Мне нужно, чтобы каждое сообщение напрямую попадало в память моего агента. Мне нужен контекст о клиенте, его предыдущих разговорах, базе знаний его компании — всё это должно быть доступно до того, как AI начнёт печатать.
Я потратил три дня, пытаясь заставить Chatwoot делать то, что мне нужно. Потом удалил интеграцию и попросил Claude собрать мне inbox.
На это ушло 90 минут.
Он делает ровно то, что мне нужно. Ни больше, ни меньше. И когда завтра я захочу добавить поддержку WhatsApp, или голосовые звонки, или любую другую странную фичу, я добавлю её за 10 минут вместо того, чтобы бороться с чужой дорожной картой.
Кейс 2: LLM-фреймворк
LangChain строит абстракции поверх LLMs, добавляет middlewares и fallbacks, экспортирует метрики и логи, оборачивает вызовы инструментов. Для базовой логики оркестрации LLM всё ещё имеет смысл использовать. Я не хочу писать свою логику повторных попыток для 12 разных модельных провайдеров. Я не хочу заново реализовывать парсинг tool calls. Эта часть — commodity, и LangChain справляется с ней достаточно хорошо.
LangSmith хорош для отладки во время разработки. Но мне нужна observability как часть продукта, а не просто developer tool. Я хочу контролировать, какие данные я храню, где я их храню, и как я их визуализирую для конечных клиентов. Я не хочу отправлять все данные разговоров пользователей третьей стороне. Я не хочу быть заблокированным их ценами или их дорожной картой.
Я потратил час на чтение документации LangSmith API, чтобы понять, какие фичи я реально использую каждый день. Потом попросил Claude собрать мне замену. На это ушло 2 часа.
Теперь у меня есть:
- Полное trace-логирование для каждого LLM-вызова
- Отслеживание стоимости по пользователям, по разговорам
- Кастомная визуализация, которая идеально вписывается в мою дашборд
- Нет внешних зависимостей, нет лишних счетов
- Возможность добавлять кастомные метрики когда угодно
Я всё ещё использую LangChain для оркестрационного слоя. Я всё ещё использую LangSmith для локальной отладки, когда добавляю новые фичи. Но для продакшена вся observability работает на моём собственном коде. И когда клиент спрашивает “можем ли мы увидеть, сколько токенов использовал этот разговор?” — я добавляю эту фичу за 10 минут вместо того, чтобы ждать 6 месяцев, пока LangSmith её выкатит.
💡 Инсайт: Используй библиотеки для скучных commodity-частей. Стой то, что делает твой продукт уникальным.
Кейс 3: Реальное время
Есть вещи, которые ты никогда не строишь сам.
Голосовые звонки. WebRTC. Эхоподавление. Сетевая устойчивость. Это не территория vibe-кода. Это такая проблема, над которой 100 инженерных команд работают 5 лет и всё равно косячат.
Я смотрел на это примерно 10 минут. Потом зарегистрировался в LiveKit и отправил им данные карты.
Они её решили. Они сделали сложную часть. Я не хочу разбираться в ICE-кандидатах. Я не хочу дебажить jitter buffers. Я не хочу думать о потере пакетов. Я просто хочу, чтобы телефонный звонок работал.
Это граница. Здесь баланс меняется.
Если это commodity-проблема, которую 1000 человек решили точно так же? Используй библиотеку. Если это твой ключевой дифференциатор? Если тебе нужно менять это каждую неделю? Если у тебя есть одно странное требование, которого ни у кого нет? Строй сам.
Кейс 4: Встроенная аналитика
И мне не нужны дашборды. Мне не нужны pivot tables. Мне не нужно делиться отчётами с инвесторами. Мне нужны ответы на очень конкретные вопросы.
“Сколько разговоров с ошибками в ценах было на прошлой неделе?” “Какое среднее время ответа по каналам?” “Сколько пользователей реально используют голосовую фичу?”
Раньше я тратил час каждую неделю на создание новых Metabase-дашбордов. Потом я понял: я могу просто попросить Claude написать мне запрос.
Я пишу “покажи среднее время ответа по каналам за последние 7 дней” и через 10 секунд у меня точные цифры. Нет дашборда. Нет настройки. Нет ожидания, пока Metabase отрендерит.
Я удалил Metabase. Сэкономил $50 в месяц. Получаю ответы быстрее. И никто всё равно не просит меня о дашбордах.
💡 Инсайт: Для соло-основателей AI превращает каждую базу данных в BI-инструмент. Тебе не нужны дашборды, когда можно получить ответы напрямую.
Компромиссы
Это не манифест против open source. Это манифест против карго-культа.
Правило, которое тебе говорят:
“Не изобретай велосипед”
Но никто не говорит мелким шрифтом:
Если изучение велосипеда занимает дольше, чем его постройка.
И с AI-кодинг-агентами эта линия движется каждый день.
Вот что я теряю, когда делаю vibe-кодинг:
- Нет боевого тестирования: Мой код для observability имеет 3 граничных случая, которые LangSmith уже исправил. Я с ними столкнусь. Я их исправлю. На каждый уйдёт 10 минут.
- Нет сообщества: Когда что-то ломается, я не могу загуглить. Я должен читать свой собственный код.
- Нет бесплатных фич: Я никогда не получу ту красивую timeline-вьюшку, которую LangSmith выкатил на прошлой неделе. Она мне не нужна.
А вот что я получаю:
- Полный контроль: Я могу изменить literally что угодно за 10 минут.
- Нет кривой обучения: Я это написал. Я понимаю каждую строку.
- Идеальное соответствие: Это делает ровно то, что мне нужно. Ни больше, ни меньше.
Вердикт
“Самая большая ложь в разработке — что ‘повторное использование кода всегда лучше’.”
Это было верно 10 лет назад. Это было верно до AI-кодинг-агентов. Это было верно, когда написать 500 строк кода занимал целый день.
Теперь написать 500 строк кода занимает 90 секунд. Теперь понять чужую абстракцию из 500 строк занимает 3 дня.
Математика изменилась.
| Задача | Open Source | Vibe-код |
|---|---|---|
| Время до работающего прототипа | 3 дня | 90 секунд |
| Время на добавление одной фичи | 8 часов | 10 минут |
| Строк кода | 10 000 | 500 |
| Время дебага, когда ломается в 2 ночи | 4 часа | 10 минут |
Это новая арифметика. Это то, что не напишет ни в одном блогпосте.
Тебе всё ещё не стоит строить свою базу данных. Тебе всё ещё не стоит строить свой WebRTC-сервер. Тебе всё ещё не стоит строить свой язык программирования.
Но для всего остального? Для всей скучной связующей логики, которая составляет 80% твоего приложения?
Просто строй её.
Гиганты, на чьих плечах ты стоишь? Они так же растеряны, как и ты. В их коде столько же багов. И теперь ты можешь написать ровно то, что нужно быстрее, чем прочитать их документацию.

Если ты соло-основатель и тратишь больше 2 часов на интеграцию библиотеки — закрой вкладку. Просто попроси AI написать это за тебя.
Ты будешь удивлён, насколько хорошо это работает.
Скажи, что я неправ. Я поспорю с каждым из вас в комментариях.