Open Knowledge Format (OKF) vs Agent Skills
Open Knowledge Format (OKF) vs Agent Skills. Узнайте, почему детерминированное исполнение превосходит статические файлы знаний для ИИ-агентов.
Мы стоим перед новым вызовом в архитектуре агентов: появились два принципиально новых открытых стандарта для определения знаний ИИ-агентов. Всего за несколько месяцев Google выпустил Open Knowledge Format (OKF), а Anthropic опубликовал Agent Skills с открытым исходным кодом.
Поскольку эти стандарты новые, отрасль ещё разбирается, как их использовать. Прежде чем внедрять любой из них, нужно понять их фундаментальные различия:
- Agent Skills (Anthropic): Разработаны для автоматической активации. Используют описание на естественном языке, чтобы модель сама решала, когда загружать навык в контекст.
- Open Knowledge Format (Google): Разработан для структурированных типизированных данных. Это как база данных концепций (например,
type: table,type: metric), где ваш код оркестрации явно определяет, что загружать.
В QuotyAI, где мы строим продакшн-агентные системы для голоса и чата, мы усвоили: выбор способа организации знаний агента — это не просто предпочтение формата, а архитектурное решение с далеко идущими последствиями.
Разница между демо-агентом и продакшн-агентом — не в модели, а в том, может ли агент выполнять код, запрашивать живые данные и детерминированно обрабатывать ошибки.
В этой статье мы определим различия между двумя новыми стандартами, рассмотрим, зачем и как их можно использовать, и разберём, когда стоит отказаться от статических файлов в пользу детерминированного рантайма.
Проблема: Откуда модели знать?
Foundation model ничего не знает про вашу таблицу orders. Он не знает, что confirmed_at — правильный таймстемп для отчётности по выручке, а не created_at. Он не знает, что таблица customers связывается по customer_id. Он не знает ваших определений метрик, внутренних API или инструкций на случай сбоя пайплайна.
Кто-то должен ему всё это объяснить. Вопрос в следующем: в каком формате, где хранить и как потреблять?
OKF и Agent Skills — два ответа на этот вопрос. У них общая ДНК, но разные архитектурные ставки.
Контекстное окно модели не бесконечно. Каждая строка немаркированного Markdown конкурирует за внимание с реальной задачей. Чем больше нерелевантного текста вы загружаете, тем сложнее модели сфокусироваться на главном — и тем вероятнее она начнёт додумывать детали из шума.
Что на самом деле делает OKF
OKF — это каталог файлов Markdown. Каждый файл представляет одну концепцию — таблицу, метрику, API, инструкцию. Единственное обязательное поле в YAML-фронтматтере — type. Всё остальное — по желанию.
---
type: table
title: orders
resource: bigquery://my-project.ecommerce.orders
tags: [ecommerce, source-of-truth]
---
Primary key: `order_id`. Joins to `customers` on `customer_id`.
Use `confirmed_at` for revenue reporting — not `created_at`, which includes abandoned carts.Бандл — это директория с такими файлами. Бандлы могут ссылаться друг на друга, так что метрика revenue может содержать ссылку на концепцию таблицы orders, из которой она вычисляется.
Нет SDK. Нет аккаунта Google Cloud. Нет рантайма. Любой инструмент, читающий директорию файлов, может потреблять OKF — это и есть явная цель дизайна.
Как агенты это потребляют: внешний оркестратор решает, что загружать. Агент может получить весь бандл в контексте, а может вызвать инструмент, который запрашивает бандл по типу или ключевым словам. Логика выбора живёт в вашем коде, а не в формате.
Что на самом деле делают Agent Skills
Skill — это папка. Внутри: SKILL.md и вспомогательные файлы — скрипты, шаблоны, примеры вывода, справочные документы.
SKILL.md решает две задачи. Поле description выступает как семантический триггер — Claude читает его и решает, подходит ли этот навык к текущей задаче. Тело содержит всё, что вы хотите, чтобы Claude знал или делал: процедуры, документацию по схемам, брендбук, SQL-паттерны.
---
name: orders-schema
description: >
Use when the task involves querying, analyzing, or joining the orders table,
including revenue calculations or customer purchase history.
---
Table location: `bigquery://my-project.ecommerce.orders`
Primary key: `order_id`. Join to `customers` on `customer_id`.
For revenue: use `confirmed_at`, not `created_at`.Когда Claude сталкивается с задачей, он читает описание каждого доступного навыка и решает, стоит ли загружать полное содержимое. Это происходит автоматически — без промпт-инжиниринга и кода оркестрации.
Ключевое архитектурное отличие от OKF: выбор делает Claude, а не ваш код. Логика активации находится в рассуждении модели.
Где масштаб ломает оба формата
Оба формата одинаково хорошо работают с знаниями и процедурами. Оба используют Markdown и YAML, хранятся в контроля версий и содержат ссылки на ресурсы. Модель контента почти идентична, но модель потребления различается:
- OKF: ваш детерминированный код оркестрации решает, что загружать, когда и для какого агента.
- Skills: вероятностная модель (Claude) решает, что загрузить, на основе соответствия задаче.
На малом масштабе оба варианта работают. Но представьте: у вас 150 таблиц в трёх доменах данных. Вот где в продакшене начинаются проблемы.
С OKF 150 таблиц — это 150 файлов. Агент, строящий запрос по выручке, загружает orders.md и revenue.md. Использование контекста масштабируется с областью задачи, а не с размером базы знаний. Это главное преимущество OKF. Но оно создаёт свою проблему: кто-то должен написать код оркестрации, который загружает нужные файлы в нужное время. Этого кода в формате нет.
С Skills нельзя упаковать 150 схем в один файл. Когда Claude активирует навык, он загружает весь SKILL.md. Один файл со 150 схемами — это значит, что каждая задача, связанная с данными, загружает все 150 схем в контекстное окно, независимо от того, к какой таблице относится задача. Поэтому приходится разделять: один навык на домен. Это работает, пока вы не загружаете весь домен ради задачи, которая нуждается лишь в одной таблице.
Нескончаемый поток немаркированного текста в контекстном окне не делает агента умнее. Он делает агента рассеянным. При масштабировании детерминированная выборка всегда побеждает вероятностные догадки.
Чего не хватает: строгие контракты и детерминизм
В QuotyAI мы рано осознали, что надёжность ИИ-агента определяется его рантайм-ограничениями. Ни OKF, ни Skills не предоставляют этих ограничений.
Чего не хватает в Skills: типизированных контрактов Skills нуждаются не только в поле описания и теле Markdown. Им не хватает того, что мы называем типизированными контрактами:
- Нет системы типов: Навык, описывающий схему, выглядит так же, как навык, определяющий многоэтапный процесс. Нет
type: knowledgeилиtype: procedure. - Нет контрактов ввода/вывода: Навык «сгенерировать SQL-запрос» может подразумевать имя таблицы и формат вывода, но Claude выводит их из текста. Нет структурированной схемы, принудительно определяющей вход и выход.
- Нет границ ошибок: Если навык завершается с ошибкой, это происходит неопределённо. Нет заданного набора кодов ошибок (
SLOT_UNAVAILABLE,CUSTOMER_NOT_FOUND), которые мог бы поймать детерминированный путь обработки ошибок.
Чего не хватает в OKF: хуков исполнения агента OKF описывает граф знаний, но не даёт агенту детерминированную карту прохода по нему.
- Концепции пассивны: Концепция таблицы
ordersне говорит агенту «загрузиrevenue.mdперед тем, как писать запрос». Агент получает концепцию и вероятностно решает, что делать дальше. Нет хуков исполнения агента. - Нет разделения design-time и runtime: Файлы OKF — это артефакт этапа проектирования, но агентам нужно рассуждение в рантайме. Файл не предоставляет детерминированный тест-раннер или интерпретатор для проверки, действительно ли агент понял концепцию.
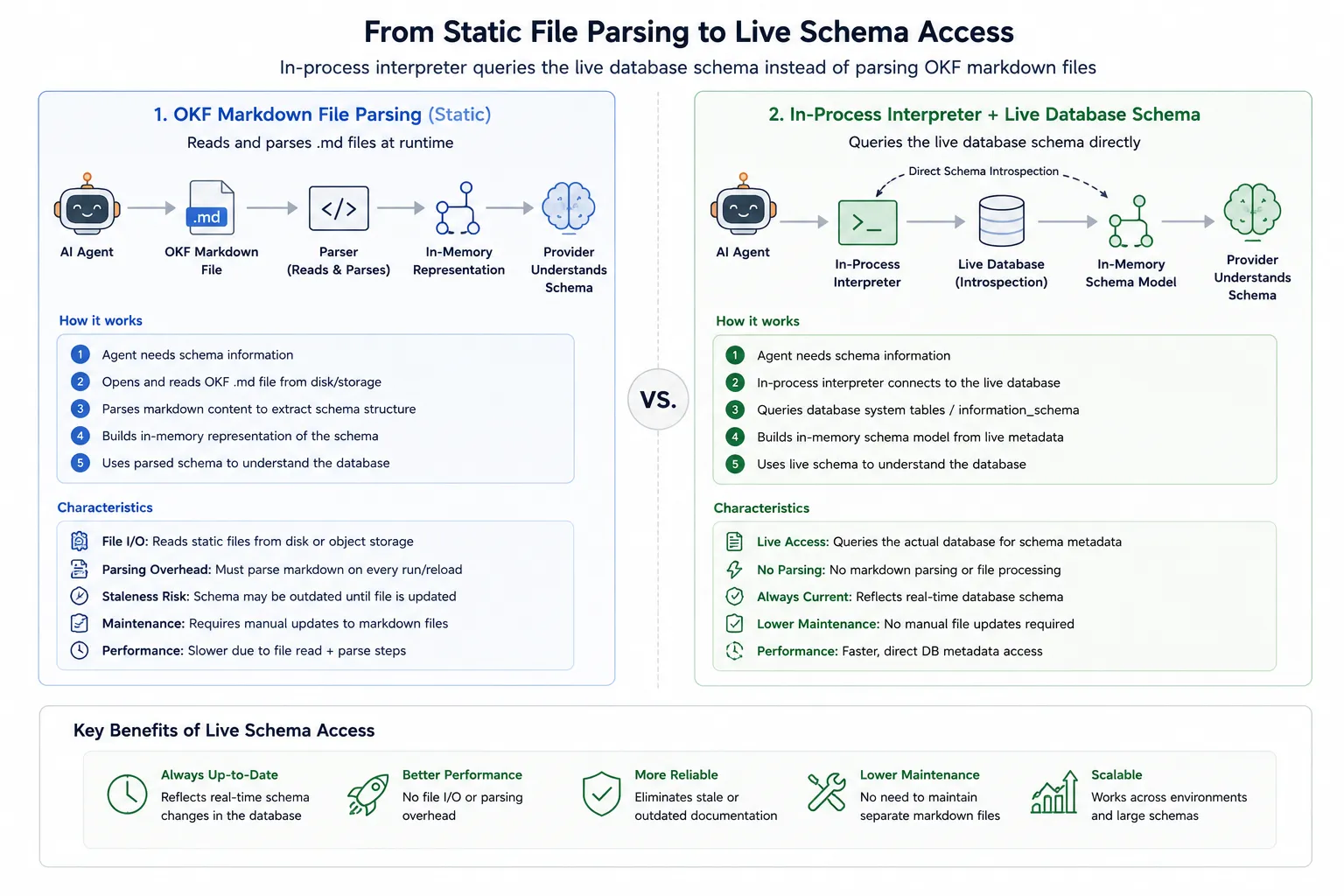
Третий путь, превосходящий оба варианта: детерминизм как инфраструктура
Есть более сильный аргумент, чем «исправить OKF, исправить Skills». Он таков: предварительно подготовленные статические файлы знаний — это неправильная единица вообще.
Волна RAG 2023 опиралась на «лучший поиск» по статическим файлам. Следующая волна агентов строится на слоях детерминированного исполнения. Более перспективное направление — агент, оснащённый интерпретатором в процессе (например, QuickJS), который вычисляет необходимое в рантайме, а не читает то, что человек написал заранее.
Когда мы внедрили интерпретатор в процессе в QuotyAI, латентность агента для маршрутизирующих решений упала со средних ~2,5 с до фиксированных 24 мс. Почему? Потому что условная логика и управление состоянием вышли из LLM и перешли в детерминированный код.
Цель не в том, чтобы модель никогда не ошибалась — а в том, чтобы быстро ловить ошибки и детерминированно восстанавливаться, не давая им молча распространяться.
Тот же принцип применим к знаниям. Глубокому агенту не нужен предписанный файл orders.md. Он пишет детерминированный вызов инструмента по information_schema, получает актуальную схему, фильтрует её в песочнице и передаёт модели три релевантных столбца вместо трёхсот. Никто не готовил этот файл. Никакой файл не может устареть.
Почему вычисляемый доступ к знаниям превосходит статические файлы OKF/Skills:
- Без устаревания. Концепция OKF — это снимок, который кто-то сделал. Актуальный запрос — это текущее состояние. В таблицу
ordersзавтра может добавиться столбец; глубокий агент, запрашивающий схему напрямую, узнает об этом сразу. - «Готово» — это схема, а не ощущение. С оценкой на основе рубрик и типизированными контрактами агент не просто читает навык и угадывает. Он исполняет код, и если критерий не пройден, детерминированный оценщик генерирует точную обратную связь.
- Меньше токенов, выше точность. OKF с файлами по концепциям превосходит избирательную загрузку Skills. Но вычисляемый ответ превосходит оба варианта. Агент не загружает описание на 200 слов в Markdown и не рассуждает о нём — он выполняет
DESCRIBE orders, получает точные имена столбцов и движется дальше.
Команды, выпускающие надёжных агентов — это не те, у кого самые большие счета за модели. Это те, у кого ИИ-инструменты и контракты читаются как схема базы данных.
Когда использовать каждый из вариантов
Несмотря на недостатки, оба формата уже можно использовать — если выбрать правильную область применения.
Используйте OKF, когда:
- У вас есть бизнес-определения, экспертные знания и «почему» за метрикой, которая не лежит в базе данных и не поддаётся прямому запросу.
- Несколько команд потребляют одни и те же типизированные знания без необходимости пересоздавать их.
Используйте Skills, когда:
- Claude — основной рантайм вашего агента.
- У вас небольшие, сфокусированные процессы, нуждающиеся в автоматической активации на основе триггеров без написания пользовательского кода оркестрации.
Используйте детерминированное исполнение кода для всего остального:
- Для всего, что носит механический характер — «как выглядит актуальная система прямо сейчас?» — используйте интерпретатор в процессе или подключение MCP. Запрашивайте актуальное состояние в рантайме вместо чтения статического файла об этом.
Такой стек использует каждый компонент по его сильной стороне. Но истинный урок здесь шире, чем выбор победителя между OKF и Skills. Лучшая архитектура агентов — это не про то, чтобы давать моделям более качественные статические markdown-файлы для чтения. Это про осознание того, что большинство «проблем формата знаний» — это на самом деле просто отсутствующая инфраструктура.
Постройте детерминированный рантайм под моделью, и проблема знаний решится сама.
Часто задаваемые вопросы
Почему OKF и Agent Skills теряют эффективность при масштабировании? При масштабировании OKF требует ручного кода оркестрации для выборки файлов, а Agent Skills заставляет модели загружать массовые, неизбирательные схемы в контекстное окно, деградируя точность рассуждений. Оба варианта — статические узкие места.
Что такое типизированный контракт навыка? Типизированный контракт навыка — это строгая схема, определяющая входы, выходы и точные границы ошибок возможности агента, переводя её из вероятностной догадки в детерминированное исполнение кода.
Как интерпретатор в процессе улучшает агентов? Интерпретатор в процессе позволяет агенту выполнять запросы напрямую и запускать код в своей песочнице. Вместо разбора статической документации агент запрашивает живую систему — получая точную текущую схему, а не устаревшее приближение.
Было полезно? Поделитесь.
Похожие статьи
Детерминизм как инфраструктура: Почему AI-рантайм важнее модели
Постройте надёжных AI-агентов, относясь к детерминированному рантайму как к базовой инфраструктуре — уроки из продакшена QuotyAI.
Читать статьюСтоимость MVP упала в 20 раз. Венчурные фонды в панике. Соло-фаундеры побеждают.
Узнайте, почему MVP за $18 тыс. меняют венчурный капитал, уничтожают «тонкие обертки» и смещают фокус стартапов на данные, дистрибуцию и доверие.
Читать статью"Детерминистская" ставка: Почему я создаю QuotyAI, который работает надёжно, а не просто "болтает".
Большинство ИИ-агентов — это продвинутые секретари, которые ломаются, когда вам нужна настоящая бизнес-логика. Вот почему я ставю всё на детерминистическую генерацию кода.
Читать статью