Детерминизм как инфраструктура: Почему AI-рантайм важнее модели
Постройте надёжных AI-агентов, относясь к детерминированному рантайму как к базовой инфраструктуре — уроки из продакшена QuotyAI.
Модели больше не главное отличие. Главное — рантайм.
Последний год я строил агентную AI-платформу. Голосовые звонки, чат-боты, sales-агенты, автоматизация workflow — системы, которые работают в продакшене, разговаривают с реальными клиентами, трогают реальные данные. Один паттерн постоянно всплывает, и я не вижу, чтобы про него много обсуждали, — вероятно, потому что он не льстит привычному рассказу о прогрессе AI.
Самые надёжные AI-системы — это не те, у которых самая умная модель. Это те, у которых самый детерминированный рантайм под капотом.
Это не хайп-тейк. Это вывод, который сам по себе вылезает из каждого отчёта о продакшен-инциденте, который я писал за последние двенадцать месяцев. Модели становятся умнее. Счета — дешевле. То, что решает, поедет ли агент в продакшен или придётся откатывать, всегда находится на один слой ниже LLM.
§ 01 — Что coding-агенты доказали про слой интерпретатора
Coding-агенты взлетели не потому, что модели перешагнули какой-то порог возможностей. LLM умели генерировать код ещё в 2021-м. Изменился рантайм под капотом — компилятор, тест-раннер, интерпретатор, который даёт однозначную обратную связь на каждую попытку.
Волне RAG 2023 года было нечего противопоставить. Поиск + генерация, без шага исполнения, без сигнала коррекции. Вся нагрузка по верификации падала на человека. Coding-агенты переложили эту нагрузку на машину.
“AI не должен быть уверенным. Ему нужен быстрый способ ошибиться.”
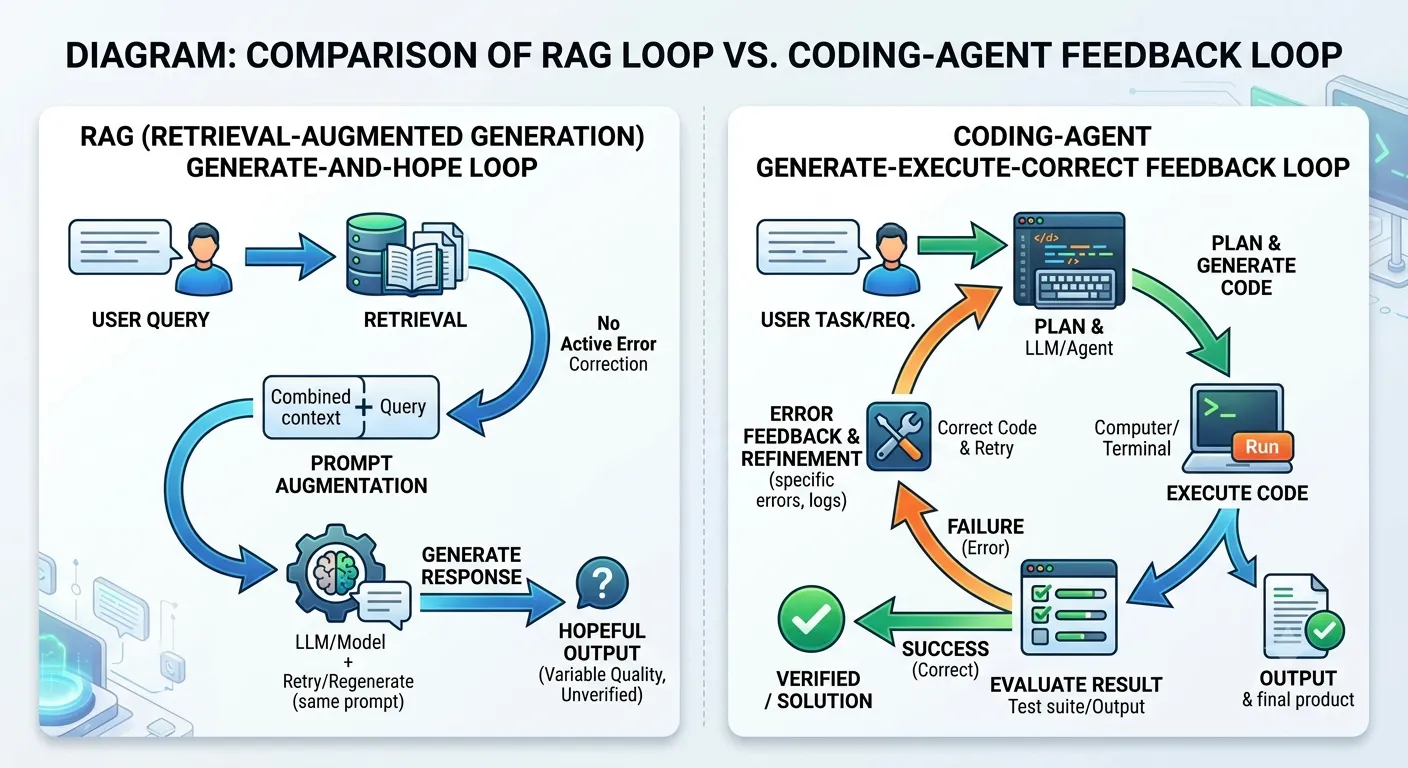
Когда вы ставите детерминированный слой исполнения под вероятностную модель, неопределённость модели перестаёт быть узким местом. Рантайм берёт на себя верификацию. Модель продолжает итерировать.
Этот паттерн обобщается. Везде, где можно прицепить детерминированный слой исполнения к LLM, вы превращаете гадание в цикл обратной связи. Coding оказался первым только потому, что слой исполнения уже существовал. Следующая волна — про осознанное построение такого слоя для каждой другой области.
💡 Уникальная идея
Coding выстрелил первым потому, что у компиляторов была фора в 50 лет. Следующей области не нужен рантайм с 50-летней историей — ей нужен хоть какой-нибудь рантайм, возвращающий правду за миллисекунды. Это инженерный проект, а не исследовательский.
Это та же интуиция, что и за детерминированной ставкой, которую я сделал при запуске QuotyAI: верь рантайму, а не разговору.
§ 02 — In-process слой интерпретатора для AI-агентов
LangChain DeepAgents поставили QuickJS in-process — JavaScript-интерпретатор внутри agent harness. AI теперь рассуждает через код как через операцию первого класса, а не через раунд-трипы во внешний раннер.
Композиция инструментов, управление состоянием, фильтрация контекста, условная оркестрация — всё детерминированное, всё внутри harness.
В QuotyAI именно это снизило задержку агента со средних ~2,5 с до фиксированных 24 мс на решениях по роутингу. Условная логика — валидация бронирований, разрешение конфликтов, правила эскалации — ушла из LLM в детерминированный код.
| Цепочка агента | Детерминированный рантайм | |
|---|---|---|
| Средняя задержка | ~2500 мс | 24 мс |
| Дисперсия | высокая | фиксированная |
| Отлаживаемость | охота за промтом | стек-трейсы |
| Стоимость решения | $0,01–$0,03 | ~$0 |
LLM занимается суждениями. Рантайм занимается фактами. Сложно тут одно — быть честным с самим собой про то, где что; и большинство команд этого не делает, потому что LLM выглядит так, будто справляется и с тем, и с другим.
§ 03 — Оценка по рубрикам: как агенты узнают, что значит “готово”
У большинства агентов нет понятия завершённости задачи. Они генерируют ответ и останавливаются. Реально ли задача выполнена — оставляется на совесть вызывающего кода.
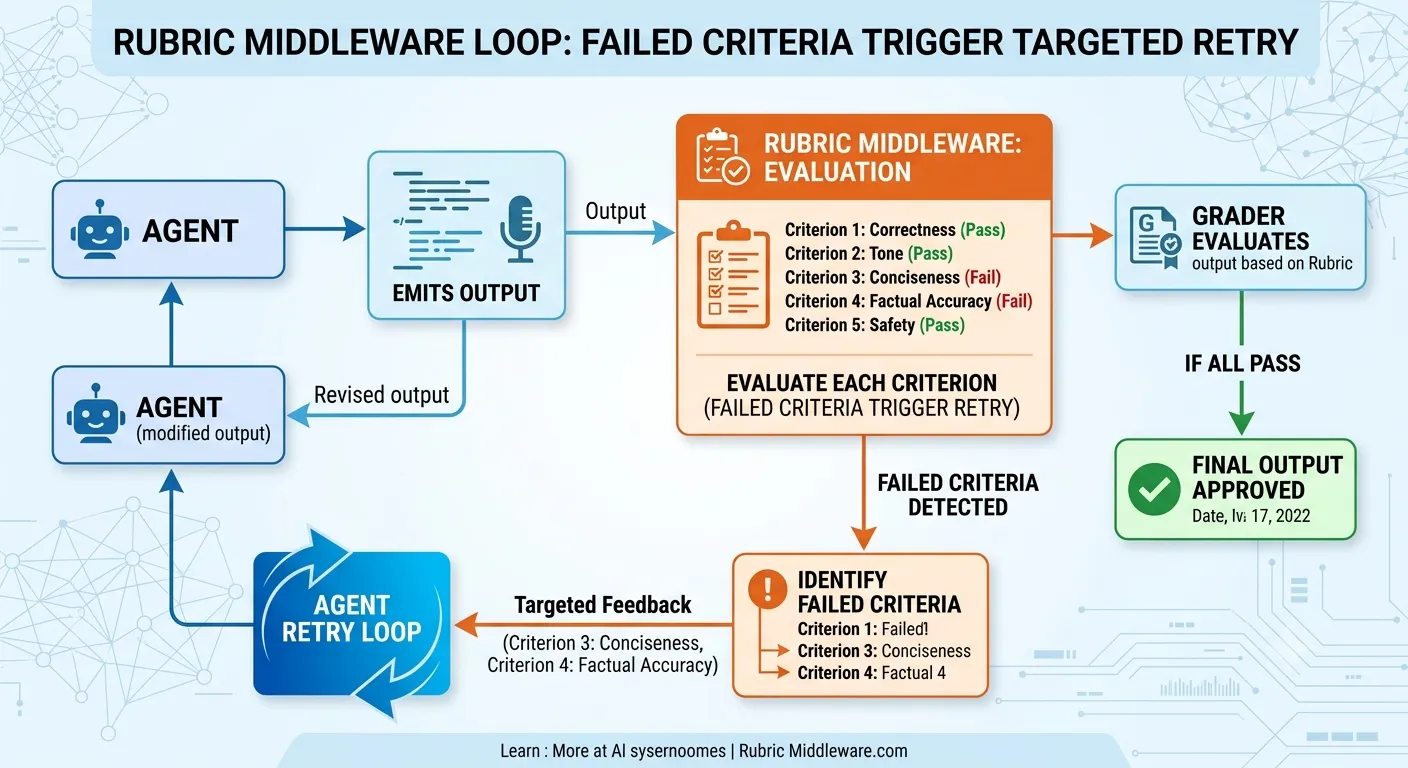
Claude Code ввёл /goal — вы задаёте цель заранее, агент явно работает в её направлении по итерациям. LangChain пошёл дальше с RubricMiddleware для DeepAgents.
Механика: суб-агент-оценщик (более дешёвая модель, специфические инструменты) оценивает вывод по типизированной рубрике до того, как ран завершится. Если какой-то критерий не пройден, оценщик инжектит обратную связь по каждому критерию — не “попробуй ещё раз”, а конкретно какой критерий упал и почему, — и цикл перезапускается.
from deepagents import RubricMiddleware, create_deep_agent
rubric = RubricMiddleware(
model="anthropic:claude-haiku-4-5", # оценщик: быстрый + дешёвый
system_prompt="Grade against rubric. Return per-criterion verdicts.",
tools=[run_test_suite, validate_schema], # оценщик может вызывать инструменты
max_iterations=5,
)
agent = create_deep_agent(
model="anthropic:claude-sonnet-4-6", # основной агент: рассуждения
middleware=[rubric],
)
result = agent.invoke({
"messages": [HumanMessage(content="Write find_duplicates(lst)")],
"rubric": (
"- All tests pass in run_test_suite\n"
"- Handles unhashable types (lists, dicts)\n"
"- Returns elements in order of first appearance\n"
),
})Два момента стоит отметить:
- Оценщик использует другую, более дешёвую модель по сравнению с основным агентом. Вы не платите за Sonnet, чтобы проверить, проходят ли тесты, — Haiku делает это с
run_test_suite. - Обратная связь покритериальная, а не общая. Агент получает не “попробуй ещё раз”, а “criterion 3 failed: crashes on unhashable input.”
“Готово” теперь — это схема, а не ощущение.
Схему вы пишете один раз. Оценщик проверяет детерминированно. Когда итерация 1 проваливает критерий 3, агент целится конкретно в этот критерий.
💡 Уникальная идея
Когда “завершено” становится схемой, отладка перестаёт быть интуицией. Вы не спрашиваете “хорошо ли отработал агент?” — вы спрашиваете “какой критерий упал и на какой итерации?”. Это тот же вопрос, на который отвечает юнит-тест, а юнит-тесты — это то, как все остальные ветки разработки выбрались из эпохи “по ощущениям”.
§ 04 — Двухфазная архитектура: контракты design-time против рассуждений runtime
Большинство команд подключают LLM, дают ей инструменты, добавляют system prompt и отгружают. Для демо это работает. В продакшене AI вызывает не ту функцию, возвращает неожиданные формы или принимает решения, которые должны были быть детерминированными.
Корневая причина: две разные фазы воспринимаются как одна.
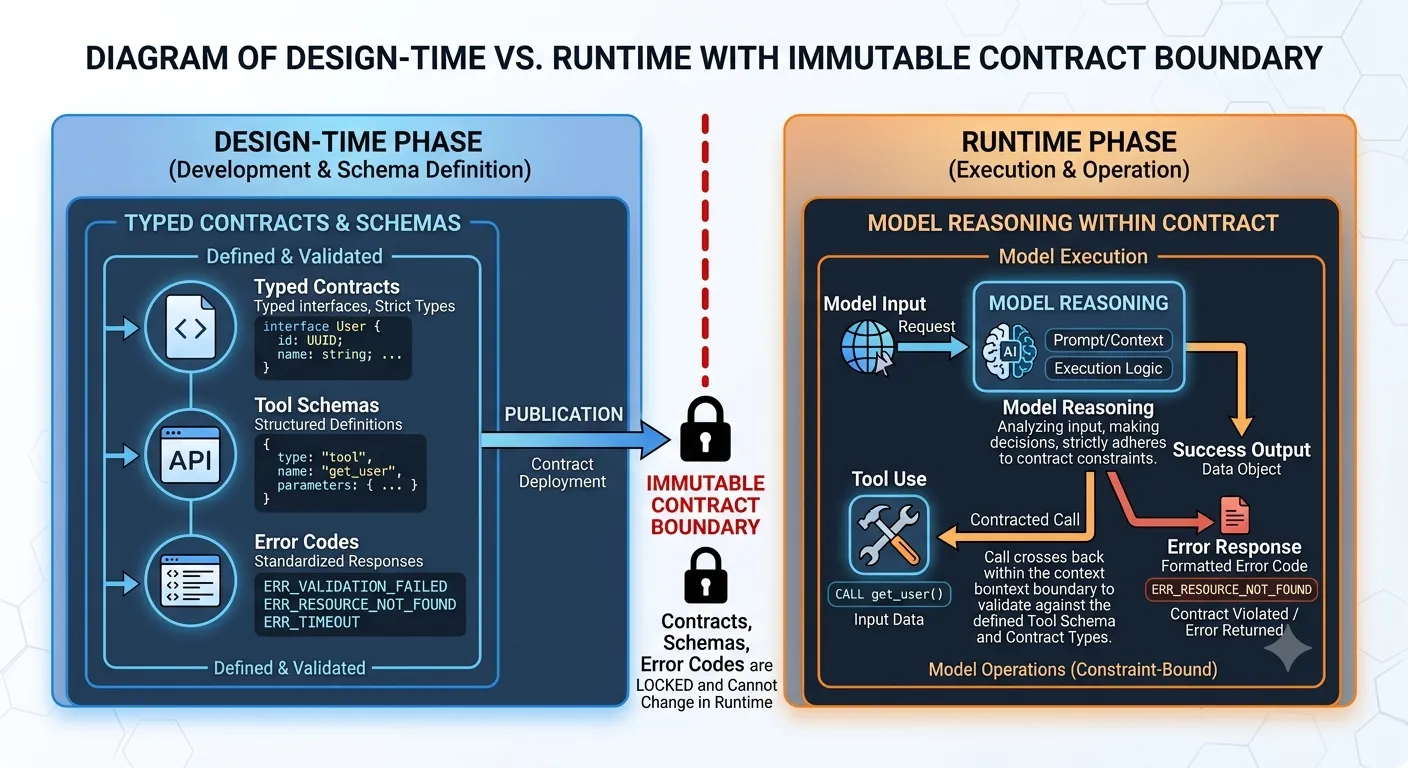
В Фазе 1 (design time) человек определяет типизированные входы/выходы, контракты инструментов, допустимые коды ошибок, версию. Это коммитится в репозиторий, покрывается тестами и считается неизменным до тех пор, пока вы не повысите версию.
В Фазе 2 (runtime) модель рассуждает внутри контракта. Вывод валидируется по схеме. Несовпадения вызывают ошибку и детерминированный фоллбэк. Бизнес-логика никогда не видит неоднозначные данные.
Награда — отлаживаемость. Когда что-то ломается: контракт неверен (Фаза 1) или модель приняла плохое решение в рамках верного контракта (Фаза 2)? Разные баги. Разные фиксы. Смешивать фазы — значит отлаживать оба одновременно, а это путь к Slack-треду длиной в шесть дней.
В QuotyAI это workflow-редактор: триггер с типизированным JSON-payload → блок условия с явной логикой → действие с определённой схемой вывода. AI маппит намерение клиента в эту структуру. Он не может выдумывать новые структуры. Контракт — это граница.
§ 05 — Типизированные контракты против MCP: выбор правильного протокола AI-инструментов
MCP — разумный ответ на реальную проблему: стандарта подключения AI к внешним инструментам не существовало. Для third-party инструментов (Slack, GitHub, Notion) он полезен.
Для логики собственного приложения он находится не на том слое.
MCP стандартизирует обнаружение и вызов инструментов. Он не даёт вам типизированных I/O-контрактов на каждый инструмент, версионирования, схем ошибок по доменам или принудительно соблюдаемых форм вывода.
Определение MCP-инструмента:
{
"inputSchema": {
"type": "object",
"properties": {
"data": { "type": "object" }
}
}
}Никакой типизации. Никакой схемы ошибок. Никакой версии. Внутрь идёт что угодно, наружу выходит что угодно.
Типизированный skill-контракт:
{
"name": "create_booking",
"version": "2.1.0",
"input": {
"customer_id": "string:uuid",
"service_id": "string:uuid",
"slot": "datetime:iso8601",
"notes": "string:optional"
},
"output": {
"booking_id": "string:uuid",
"slot_confirmed": "datetime:iso8601"
},
"errors": ["SLOT_UNAVAILABLE", "CUSTOMER_NOT_FOUND", "SERVICE_DISABLED"]
}Контракт исполнения: AI выдаёт структурированный вывод → код валидирует его по схеме → несовпадение вызывает ошибку и ретрай → ничто неоднозначное не доходит до бизнес-логики.
MCP будет расти для third-party-коннективности. Кастомные контракты выиграют для first-party-логики, потому что именно они делают вывод AI поддающимся аудиту. Аудитор не хочет читать промты. Он хочет читать схему и лог того, какая версия схемы вернула какой вывод на какой ввод.
§ 06 — Роутинг моделей как управляемая инфраструктура
Одна модель на любую задачу — это бухгалтерский провал.
| Задача | Модель | Задержка | Стоимость вызова |
|---|---|---|---|
| Классификация intent | claude-haiku-4-5 | ~150 мс | $0,001 |
| Генерация ответа | claude-sonnet-4-6 | ~1,5 с | $0,015 |
| Обработка чувствительных PII | llama-3-8b (self-hosted) | ~400 мс | $0 |
Это разные ограничения. Гонять Sonnet на каждый вызов классификации — дорого и медленно. Гонять Haiku на сложную задачу рассуждения — получать уверенно неправильные ответы.
MODEL_ROUTES = {
"intent_classification": {
"model": "claude-haiku-4-5",
"max_tokens": 100,
"latency_budget_ms": 200,
},
"response_generation": {
"model": "claude-sonnet-4-6",
"max_tokens": 1000,
"latency_budget_ms": 2000,
},
"sensitive_data": {
"model": "llama-3-8b", # self-hosted — данные не покидают периметр
"max_tokens": 500,
"private": True,
},
}
def call_agent(task_type: str, payload: dict):
config = MODEL_ROUTES[task_type]
return call_model(config["model"], payload, config)Это не фича для пользователя. Это решение по роутингу до любого вызова LLM. Большинство команд этого не делает, потому что фреймворки не принуждают. Разрыв по задержке и стоимости между уровнями слишком большой, чтобы игнорировать на масштабе, — и он растёт с каждым релизом моделей, потому что фронтир-модели и edge-модели перестают сходиться по цене, как только включается специализация.
Для голосового канала это вообще не обсуждается. 1,5 с ответа ощущаются естественно в чате и сломанно — в телефонном звонке. Слой роутинга — это то, что позволяет одному и тому же агенту обслуживать оба сценария.
§ 07 — Что строится на детерминированном AI-фундаменте
Волна RAG 2023 года строила лучший поиск. Потолок был — “поиск получше”.
То, что строится на детерминированном фундаменте, отличается по сути — AI исполняет, а не синтезирует.
Schema-first agent-фреймворки. Вы будете определять AI-контракты так же, как сейчас определяете схемы баз данных, — с валидацией, версионированием и тулингом для миграций. Слой схем будет CLI-артефактом, а не system prompt’ом.
Rubric-based CI/CD для агентов. Перед мерджем изменения в наборе инструментов агента или версии модели прогоняется тест-сьют по рубрикам. Зелёный — значит агент по-прежнему удовлетворяет определённым критериям завершённости. Тот же паттерн, что и юнит-тесты, только применённый к поведению агента.
Роутинг моделей как управляемый слой. Маппинг “тип задачи → выбор модели” уходит ниже слоя приложения целиком, как DNS лежит ниже HTTP. Ваше приложение не будет знать, какая модель отработала, — только то, что контракт удовлетворён.
💡 Уникальная идея
Команды, которые в 2026-м поставляют надёжных агентов, — это не те, у кого самые большие счета за модели. Это те, чьи контракты можно читать как схему базы данных. Интересная инфраструктура — та, которую вы не видите в демо.
Глубже мысль такая: ценность не в модели. Модели улучшаются непрерывно, и лучшие из них продолжают дешеветь. Ценность — в рантайме, который делает вывод модели достаточно надёжным, чтобы на него действовать: типизированные контракты, детерминированное исполнение, проверяемая завершённость.
Этот рантайм строится прямо сейчас. В основном тихо. В основном теми, кто обжёгся на первой волне.
Часто задаваемые вопросы
Q: Почему детерминированные рантаймы важнее более умных моделей для AI-агентов? A: Более умные модели всё равно нуждаются в быстром способе ошибиться. Детерминированный рантайм — компилятор, интерпретатор, валидатор — даёт каждой догадке однозначный вердикт, поэтому модель итерирует, а не галлюцинирует. Потолок надёжности задаётся рантаймом, а не количеством параметров.
Q: Как in-process интерпретатор вроде QuickJS делает агентов надёжнее? A: In-process интерпретатор позволяет агенту рассуждать через код как через операцию первого класса. Композиция инструментов, управление состоянием и условная логика становятся детерминированным исполнением вместо вероятностной генерации. В QuotyAI это снизило задержку агента с ~2,5 с до фиксированных 24 мс для решений по роутингу.
Q: Что такое типизированный skill-контракт и чем он отличается от MCP? A: Типизированный skill-контракт жёстко фиксирует форму ввода, форму вывода, версию и точный набор допустимых ошибок для одного инструмента. MCP стандартизирует обнаружение и вызов инструментов, но оставляет I/O слабо типизированным. Для логики first-party приложений типизированные контракты делают вывод AI поддающимся аудиту; MCP — правильный слой для third-party коннекторов вроде Slack или GitHub.
Я строю QuotyAI — агентную AI-платформу для voice, чата и бизнес-автоматизации. Если вы работаете над детерминированной инфраструктурой агентов, попробуйте бесплатно — и мне интересно услышать, что вы видите со своей стороны.
Ссылки
Было полезно? Поделитесь.
Похожие статьи
Open Knowledge Format (OKF) vs Agent Skills
Open Knowledge Format (OKF) vs Agent Skills. Узнайте, почему детерминированное исполнение превосходит статические файлы знаний для ИИ-агентов.
Читать статьюКак я запускаю продающий AI-стартап за $30 в месяц
Запустите продающий AI SaaS-стартап за $30/месяц с этим стеком для одного основателя, используя бесплатные уровни, AI-ассистентов и простую инфраструктуру без Kubernetes.
Читать статьюПервая миссия QuotyAI: Конкретная проблема, которую я решаю для первых 2 компаний
Создаю детерминированную поддержку клиентов для гестхаусов и ресторанов. Сокращаю неявки на 70% и возвращаю владельцам малого бизнеса 3 часа в день с абсолютно точными ответами.
Читать статью