Determinism như Hạ Tầng: Tại Sao AI Runtime Quan Trọng Hơn Model
Xây dựng AI agents đáng tin cậy bằng cách xem deterministic runtime như hạ tầng cốt lõi—bài học từ production của stack voice và chat tại QuotyAI.
Models không còn là điểm khác biệt nữa. Runtime mới là.
Tôi đã dành cả năm qua để xây dựng một agentic AI platform. Cuộc gọi voice, chatbot, sales agent, tự động hóa workflow — những hệ thống chạy trong production, nói chuyện với khách hàng thật, đụng vào dữ liệu thật. Một pattern cứ lặp lại mà tôi không thấy ai bàn nhiều, có lẽ vì nó không nịnh tai cái câu chuyện quen thuộc về tiến bộ AI.
Những hệ thống AI đáng tin cậy nhất không phải là những hệ thống có model thông minh nhất. Chúng là những hệ thống có runtime deterministic nhất bên dưới.
Đây không phải là một quan điểm gây sốc. Nó là thứ rơi ra từ mọi báo cáo sự cố production tôi viết trong mười hai tháng qua. Models càng ngày càng thông minh. Bill càng ngày càng rẻ. Cái thứ quyết định agent có ship được hay phải rollback luôn nằm ở một tầng bên dưới LLM.
§ 01 — Coding Agents Đã Chứng Minh Điều Gì Về Tầng Interpreter
Coding agents không cất cánh vì models vượt qua một ngưỡng năng lực nào đó. LLMs đã đủ khả năng sinh code từ năm 2021. Cái đã thay đổi là runtime bên dưới — một compiler, một test runner, một interpreter trả lại phản hồi rõ ràng cho mỗi lần thử.
Làn sóng RAG 2023 không có thứ tương đương. Retrieval + generation, không có bước thực thi, không có tín hiệu sửa lỗi. Toàn bộ gánh nặng xác minh đổ lên con người. Coding agents chuyển gánh nặng đó sang máy.
“AI không cần phải chắc chắn. Nó cần một cách để sai thật nhanh.”
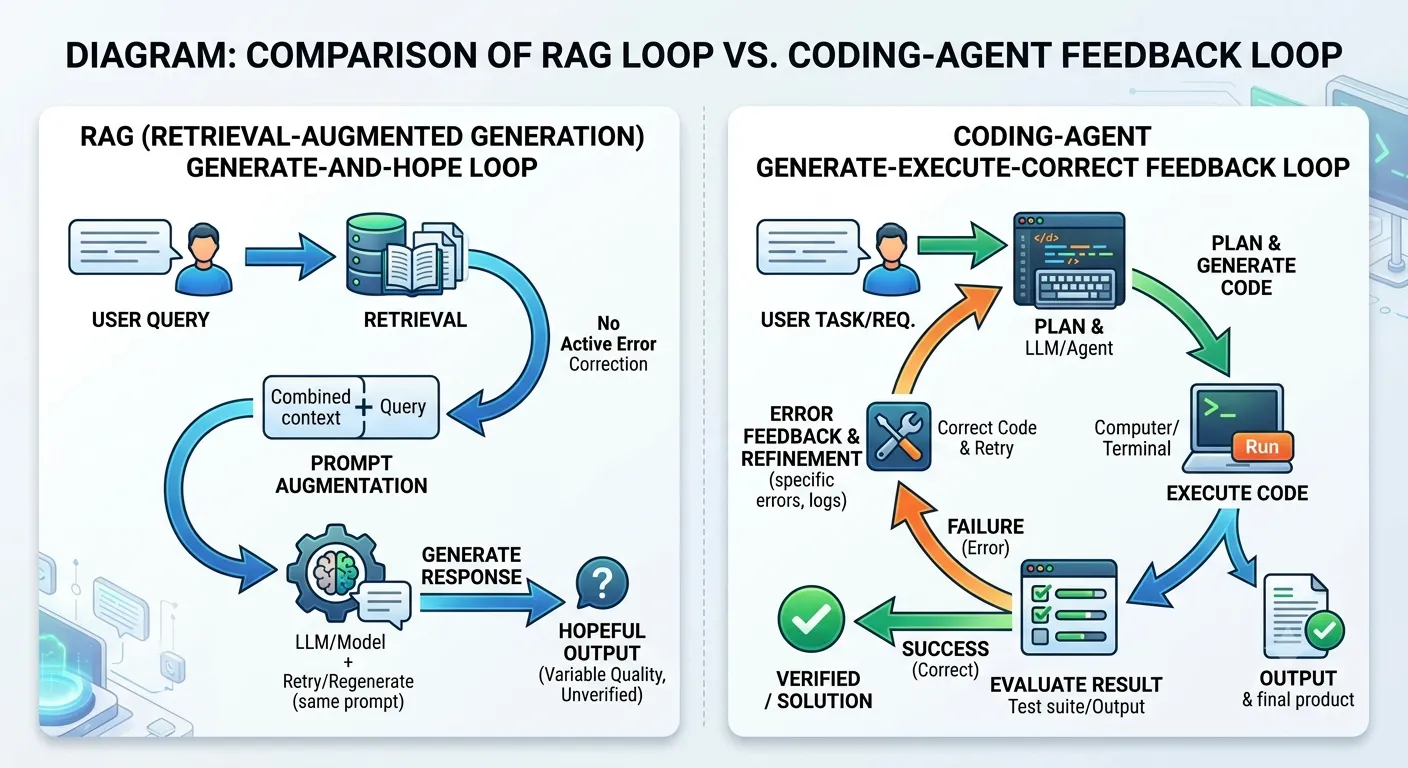
Khi bạn đặt một tầng thực thi deterministic dưới một model xác suất, sự không chắc chắn của model thôi không còn là nút thắt cổ chai. Runtime lo việc xác minh. Model cứ tiếp tục lặp lại.
Pattern này tổng quát hóa được. Ở bất cứ đâu bạn có thể gắn một tầng thực thi deterministic vào LLM, bạn biến việc đoán mò thành một vòng phản hồi. Coding là lĩnh vực đầu tiên vì tầng thực thi đã sẵn có. Làn sóng tiếp theo là về việc cố tình xây dựng nó cho mọi lĩnh vực khác.
💡 Insight Độc Đáo
Coding thành công đầu tiên vì compilers đã có 50 năm khởi động trước. Lĩnh vực tiếp theo không cần một runtime 50 năm tuổi — nó cần bất kỳ runtime nào trả lại sự thật trong vài mili-giây. Đó là một dự án kỹ thuật, không phải dự án nghiên cứu.
Đây cũng chính là trực giác đứng sau cược deterministic tôi đặt khi QuotyAI khởi sự: tin runtime, đừng tin cuộc hội thoại.
§ 02 — Tầng Interpreter In-Process cho AI Agents
LangChain DeepAgents đã ship QuickJS in-process: một JavaScript interpreter bên trong agent harness. AI giờ suy luận thông qua code như một thao tác hạng nhất — không cần round-trip đến một runner bên ngoài.
Tool composition, quản lý state, lọc context, điều phối điều kiện: tất cả đều deterministic, tất cả nằm bên trong harness.
Tại QuotyAI, đây là thứ đã đưa độ trễ agent từ trung bình ~2,5s xuống cố định 24ms cho các quyết định routing. Logic điều kiện — xác thực đặt lịch, giải quyết xung đột, quy tắc escalation — đã được lấy ra khỏi LLM và đưa vào code deterministic.
| Chuỗi agent | Runtime deterministic | |
|---|---|---|
| Độ trễ trung bình | ~2.500ms | 24ms |
| Phương sai | cao | cố định |
| Khả năng debug | săn prompt | stack trace |
| Chi phí mỗi quyết định | $0,01–$0,03 | ~$0 |
LLM lo phán xét. Runtime lo sự thật. Phần khó là thành thật về việc cái nào là cái nào — và hầu hết các đội không làm vậy, vì LLM trông như đang lo cả hai.
§ 03 — Đánh Giá Dựa Trên Rubric: Cách Agents Học Khái Niệm “Hoàn Thành”
Hầu hết agents không có khái niệm về việc hoàn thành task. Chúng sinh ra một response rồi dừng. Việc task có thật sự xong hay không bị bỏ lại cho caller.
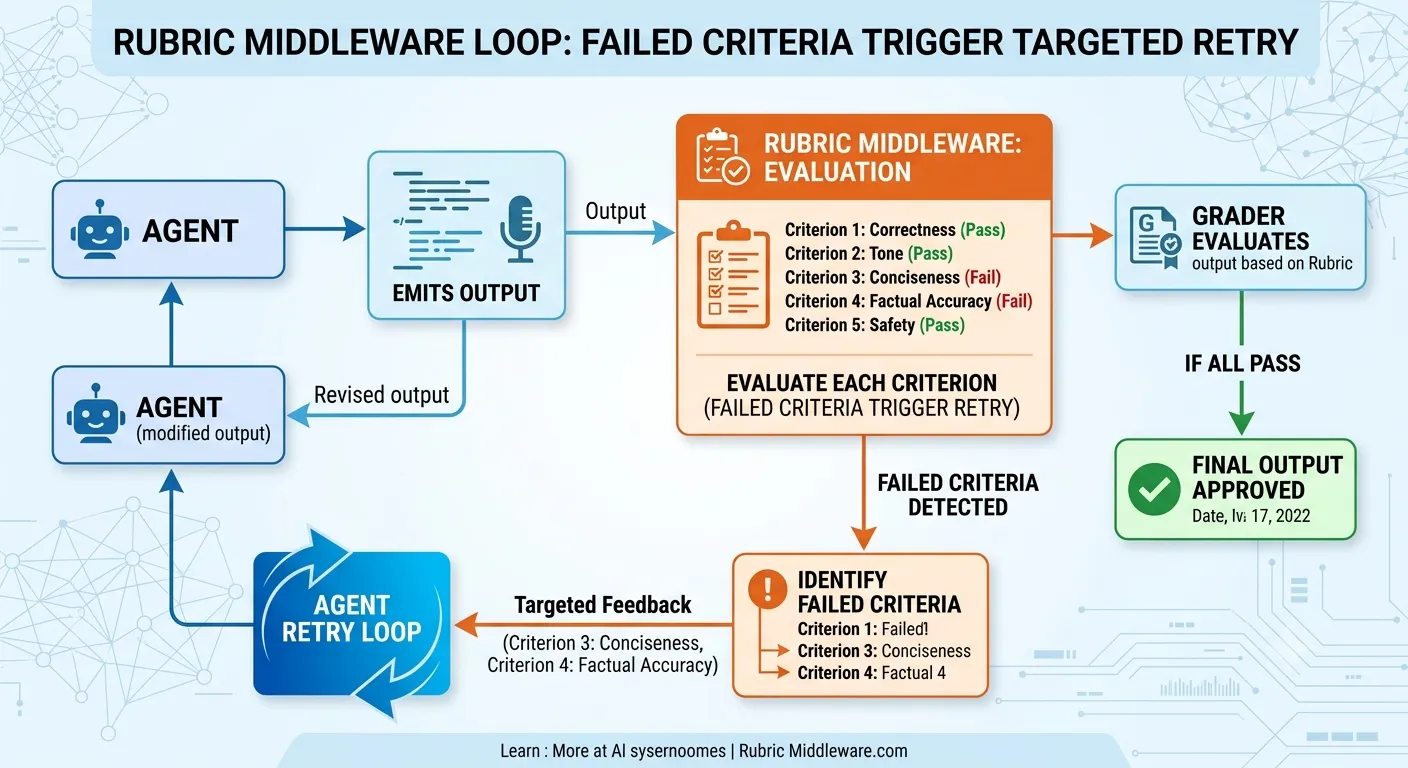
Claude Code đã giới thiệu /goal — bạn định nghĩa một mục tiêu lên trước, agent làm việc hướng đến nó một cách rõ ràng qua các iteration. LangChain đi xa hơn với RubricMiddleware cho DeepAgents.
Cơ chế: một grader sub-agent (model rẻ hơn, tool cụ thể) đánh giá output dựa trên một rubric có kiểu trước khi run kết thúc. Nếu bất kỳ tiêu chí nào fail, grader inject feedback theo từng tiêu chí — không phải “thử lại đi”, mà là chính xác tiêu chí nào fail và tại sao — rồi vòng lặp chạy lại.
from deepagents import RubricMiddleware, create_deep_agent
rubric = RubricMiddleware(
model="anthropic:claude-haiku-4-5", # grader: nhanh + rẻ
system_prompt="Grade against rubric. Return per-criterion verdicts.",
tools=[run_test_suite, validate_schema], # grader có thể gọi tool
max_iterations=5,
)
agent = create_deep_agent(
model="anthropic:claude-sonnet-4-6", # agent chính: suy luận
middleware=[rubric],
)
result = agent.invoke({
"messages": [HumanMessage(content="Write find_duplicates(lst)")],
"rubric": (
"- All tests pass in run_test_suite\n"
"- Handles unhashable types (lists, dicts)\n"
"- Returns elements in order of first appearance\n"
),
})Hai điểm đáng chú ý:
- Grader dùng một model khác, rẻ hơn so với agent chính. Bạn không trả tiền cho Sonnet để kiểm tra xem test pass hay không — Haiku làm việc đó với
run_test_suite. - Feedback theo từng tiêu chí, không chung chung. Agent không nhận “thử lại đi” — nó nhận “criterion 3 failed: crashes on unhashable input.”
“Done” giờ là một schema, không phải một cảm giác.
Bạn viết schema một lần. Grader đánh giá deterministic. Khi iteration 1 fail criterion 3, agent nhắm lại đúng criterion đó.
💡 Insight Độc Đáo
Khi “hoàn thành” trở thành một schema, debug thôi không còn là trực giác. Bạn không hỏi “agent có làm tốt không?” — bạn hỏi “criterion nào fail, ở iteration nào?”. Đó là cùng câu hỏi mà một unit test trả lời, và unit test là cách mọi nhánh khác của kỹ thuật phần mềm thoát ra khỏi kỷ nguyên “cảm tính”.
§ 04 — Kiến Trúc Hai Pha: Contracts Lúc Thiết Kế vs Suy Luận Lúc Runtime
Hầu hết các đội nối một LLM, đưa cho nó tool, thêm một system prompt, rồi ship. Cách này chạy được cho demo. Trong production, AI gọi sai function, trả về shape ngoài dự tính, hoặc đưa ra những quyết định lẽ ra phải deterministic.
Nguyên nhân gốc: hai pha riêng biệt bị đối xử như một.
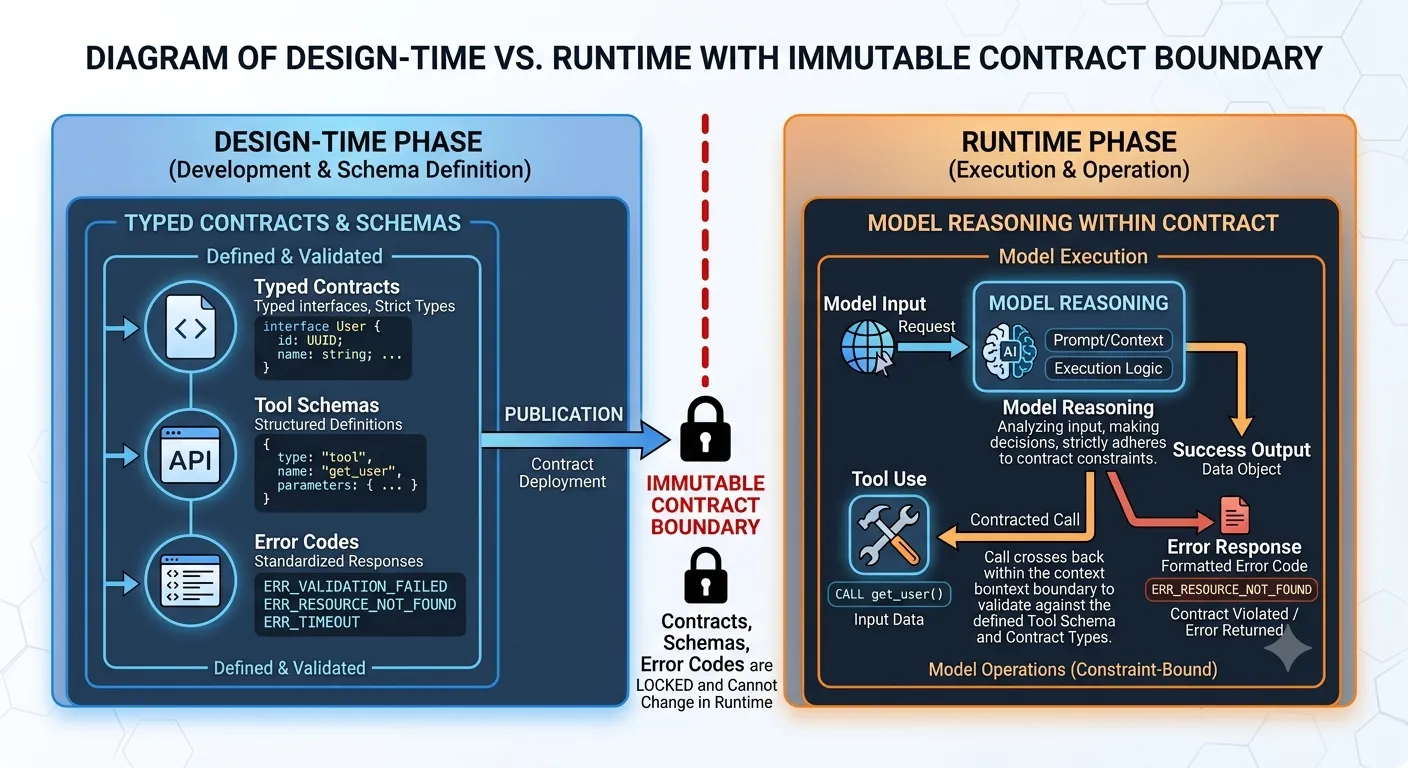
Ở Pha 1 (design time), con người định nghĩa input/output có kiểu, contract của tool, tập error code được phép, version. Cái này được check vào repo, có test, và được coi như bất biến cho đến khi bạn bump version.
Ở Pha 2 (runtime), model suy luận trong contract. Output được validate theo schema. Sai khớp kích hoạt error và một fallback path deterministic. Business logic không bao giờ nhìn thấy dữ liệu mơ hồ.
Lợi ích là khả năng debug. Khi có gì đó hỏng: contract sai (Pha 1) hay là model đưa ra quyết định tệ trong một contract đúng (Pha 2)? Hai bug khác nhau. Hai cách fix khác nhau. Trộn hai pha lại nghĩa là debug cả hai cùng lúc, và đó là cách bạn kết thúc trong một Slack thread kéo dài sáu ngày.
Tại QuotyAI đây là workflow editor: trigger với payload JSON có kiểu → condition block với logic rõ ràng → action với output schema đã định nghĩa. AI map ý định khách hàng vào cấu trúc đó. Nó không thể tự nghĩ ra cấu trúc mới. Contract là ranh giới.
§ 05 — Typed Contracts vs MCP: Chọn Đúng Giao Thức AI Tool
MCP là một câu trả lời hợp lý cho một vấn đề có thật — chưa có chuẩn nào để kết nối AI với các tool bên ngoài. Cho các tool third-party (Slack, GitHub, Notion) nó hữu ích.
Cho logic ứng dụng first-party, nó nằm sai tầng.
MCP chuẩn hóa việc khám phá và gọi tool. Nó không cho bạn typed I/O contract cho từng tool, không có versioning, không có error schema theo domain, không có ép buộc output shape.
MCP tool definition:
{
"inputSchema": {
"type": "object",
"properties": {
"data": { "type": "object" }
}
}
}Không ép kiểu. Không có error schema. Không có version. Cái gì vào cũng được, cái gì ra cũng được.
Typed skill contract:
{
"name": "create_booking",
"version": "2.1.0",
"input": {
"customer_id": "string:uuid",
"service_id": "string:uuid",
"slot": "datetime:iso8601",
"notes": "string:optional"
},
"output": {
"booking_id": "string:uuid",
"slot_confirmed": "datetime:iso8601"
},
"errors": ["SLOT_UNAVAILABLE", "CUSTOMER_NOT_FOUND", "SERVICE_DISABLED"]
}Hợp đồng thực thi: AI phát output có cấu trúc → code validate theo schema → sai khớp kích hoạt error + retry → không có gì mơ hồ chạm đến business logic.
MCP sẽ phát triển cho kết nối third-party. Custom contract sẽ thắng cho logic first-party, vì chúng là thứ làm cho output AI có thể audit được. Một auditor không muốn đọc prompt. Họ muốn đọc một schema và một log ghi rõ schema version nào đã trả output nào cho input nào.
§ 06 — Model Routing như Hạ Tầng Được Quản Lý
Một model cho mọi task là một thất bại về kế toán.
| Task | Model | Độ trễ | Chi phí/lần gọi |
|---|---|---|---|
| Phân loại intent | claude-haiku-4-5 | ~150ms | $0,001 |
| Sinh response | claude-sonnet-4-6 | ~1,5s | $0,015 |
| Xử lý PII nhạy cảm | llama-3-8b (tự host) | ~400ms | $0 |
Đây không phải là cùng một ràng buộc. Chạy Sonnet cho mọi lần gọi phân loại vừa đắt vừa chậm. Chạy Haiku cho một task suy luận phức tạp cho bạn câu trả lời sai một cách tự tin.
MODEL_ROUTES = {
"intent_classification": {
"model": "claude-haiku-4-5",
"max_tokens": 100,
"latency_budget_ms": 200,
},
"response_generation": {
"model": "claude-sonnet-4-6",
"max_tokens": 1000,
"latency_budget_ms": 2000,
},
"sensitive_data": {
"model": "llama-3-8b", # tự host — không có dữ liệu nào rời đi
"max_tokens": 500,
"private": True,
},
}
def call_agent(task_type: str, payload: dict):
config = MODEL_ROUTES[task_type]
return call_model(config["model"], payload, config)Đây không phải là một tính năng người dùng nhìn thấy. Đó là một quyết định routing trước bất kỳ lần gọi LLM nào. Hầu hết các đội không làm vậy vì framework không ép. Khoảng cách về độ trễ và chi phí giữa các tier quá lớn để bỏ qua ở quy mô lớn — và khoảng cách đó nới rộng sau mỗi lần ra model mới, vì model frontier và model edge ngừng hội tụ về giá ngay khi specialization xuất hiện.
Đối với kênh voice cụ thể, đây là điều không thể thương lượng. 1,5s response cảm thấy tự nhiên trong chat và bị hỏng trên cuộc gọi điện thoại. Tầng routing là cái cho phép cùng một agent phục vụ cả hai.
§ 07 — Cái Gì Sẽ Được Xây Dựng Trên Nền Tảng AI Deterministic
Làn sóng RAG 2023 xây dựng search tốt hơn. Trần là “tra cứu tốt hơn.”
Cái được xây dựng trên một nền tảng deterministic khác về bản chất — AI thực thi, không tổng hợp.
Schema-first agent framework. Bạn sẽ định nghĩa AI contract giống cách bạn hiện đang định nghĩa database schema — với validation, versioning và tooling cho migration. Tầng schema sẽ là một CLI artifact, không phải một system prompt.
Rubric-based agent CI/CD. Trước khi merge một thay đổi vào bộ tool hay version model của agent, một bộ test rubric chạy. Xanh nghĩa là agent vẫn thỏa mãn các tiêu chí hoàn thành đã định nghĩa. Cùng pattern như unit test, áp vào hành vi agent.
Model routing như một tầng được quản lý. Task-type → model selection chuyển xuống hẳn dưới tầng ứng dụng, giống cách DNS nằm dưới HTTP. Ứng dụng của bạn sẽ không biết model nào đã chạy — chỉ biết contract đã được thỏa mãn.
💡 Insight Độc Đáo
Những đội ship agent đáng tin cậy trong năm 2026 không phải là những đội có bill model lớn nhất. Họ là những đội mà contract của họ bạn có thể đọc như một database schema. Hạ tầng thú vị là hạ tầng bạn không nhìn thấy trong bản demo.
Điểm sâu hơn: giá trị không nằm ở model. Models cải thiện liên tục và những model tốt nhất ngày càng rẻ. Giá trị nằm ở runtime làm cho output model đáng tin cậy đến mức có thể hành động — typed contract, thực thi deterministic, hoàn thành có thể kiểm chứng.
Runtime đó đang được xây ngay lúc này. Phần lớn trong im lặng. Phần lớn bởi những người đã bị làn sóng đầu tiên thiêu rụi.
Câu Hỏi Thường Gặp
H: Tại sao deterministic runtime quan trọng hơn các model thông minh hơn đối với AI agents? A: Các model thông minh hơn vẫn cần một cách để sai thật nhanh. Một deterministic runtime — compiler, interpreter, validator — đưa ra phán quyết rõ ràng cho mỗi lần đoán, để model lặp lại thay vì ảo giác. Trần độ tin cậy được đặt bởi runtime, không phải bởi số lượng tham số.
H: Một interpreter in-process như QuickJS làm cho agents đáng tin cậy hơn như thế nào? A: Một interpreter in-process cho phép agent suy luận thông qua mã như một thao tác hạng nhất. Tool composition, quản lý state và logic điều kiện trở thành thực thi deterministic thay vì sinh ra xác suất. Tại QuotyAI điều này đã đưa độ trễ agent từ ~2,5s xuống cố định 24ms cho các quyết định routing.
H: Typed skill contract là gì và nó khác MCP như thế nào? A: Một typed skill contract chốt cứng input shape, output shape, version và tập lỗi được phép chính xác cho một tool. MCP chuẩn hóa việc khám phá và gọi tool nhưng để I/O lỏng lẻo về kiểu. Đối với logic ứng dụng first-party, typed contracts khiến đầu ra AI có thể audit được; MCP là tầng phù hợp cho các connector third-party như Slack hay GitHub.
Tôi đang xây dựng QuotyAI — một agentic AI platform cho voice, chat và tự động hóa doanh nghiệp. Nếu bạn đang làm việc trên hạ tầng deterministic agent, dùng thử miễn phí và tôi muốn nghe những gì bạn đang thấy.
Tài Liệu Tham Khảo
Bài viết hữu ích? Hãy chia sẻ.
Bài viết liên quan
Open Knowledge Format (OKF) so với Agent Skills
Open Knowledge Format (OKF) so với Agent Skills. Tìm hiểu tại sao thực thi xác định ưu việt hơn file kiến thức tĩnh cho AI agent.
Đọc bài viếtChi phí làm MVP giảm 20 lần. VC hoảng loạn. Solo Founder lên ngôi.
Khám phá lý do tại sao những MVP 18.000$ đang định hình lại ngành đầu tư mạo hiểm, kết liễu các startup 'bình mới rượu cũ' và dịch chuyển lợi thế cạnh tranh sang dữ liệu, phân phối và sự tin cậy.
Đọc bài viếtCược Deterministic: Tại Sao Tôi Xây Dựing QuotyAI Để Đáng Tin Cậy, Không Chỉ Nói Chuyện
Hầu hết các AI agent là lễ tân tinh vi mà hỏng khi bạn cần logic kinh doanh thực sự. Đây là lý do tôi cược tất cả vào tạo mã deterministic.
Đọc bài viết