We now face a new challenge in agent architecture: we have two brand new open standards for defining AI agent knowledge. In the span of a few months, Google released the Open Knowledge Format (OKF) and Anthropic open-sourced Agent Skills.
Because these standards are new, the industry is still figuring out how to use them. Before adopting either, you need to understand their fundamental differences:
- Agent Skills (Anthropic): Designed for automatic triggering. It uses a natural language description to let the model decide when to load the skill into its context.
- Open Knowledge Format (Google): Designed for structured typed data. It acts like a database of concepts (e.g.,
type: table,type: metric) where your orchestration code explicitly decides what to fetch.
At QuotyAI, building production agentic systems for voice and chat has taught us that choosing how to structure agent knowledge isn’t just a formatting preference—it’s an architectural bet.
The difference between a demo agent and a production agent isn’t the model — it’s whether the agent can execute code, query live data, and handle errors deterministically.
In this article, we’ll define the differences between these two new standards, look at why and how you might use them, and explore when you should skip static files entirely in favor of a deterministic runtime.
The Problem: How Does the Model Know?
A foundation model knows nothing about your orders table. It doesn’t know that confirmed_at is the right timestamp for revenue reporting, not created_at. It doesn’t know that the customers table joins on customer_id. It doesn’t know your metric definitions, your internal APIs, or the runbook for when the pipeline fails.
Someone has to tell it. The question is: in what format, stored where, consumed how?
OKF and Agent Skills are two answers to that question. They share DNA but make different architectural bets.
A model’s context window isn’t infinite. Every line of untyped Markdown you add competes for attention with the actual task. The more irrelevant text you load, the harder it is for the model to focus on what matters — and the more likely it fabricates details from the noise.
What OKF Actually Does
OKF is a directory of Markdown files. Each file represents one concept — a table, a metric, an API, a runbook. The only required field in the YAML frontmatter is type. Everything else is optional.
---
type: table
title: orders
resource: bigquery://my-project.ecommerce.orders
tags: [ecommerce, source-of-truth]
---
Primary key: `order_id`. Joins to `customers` on `customer_id`.
Use `confirmed_at` for revenue reporting — not `created_at`, which includes abandoned carts.A bundle is a directory of these files. Bundles can cross-reference each other, so a revenue metric concept can link to the orders table concept it’s computed from.
No SDK. No Google Cloud account. No runtime. Any tool that reads a directory of files consumes OKF — that’s the explicit design goal.
How agents consume it: the external orchestrator decides what to fetch. An agent might receive the whole bundle in its context, or it might call a tool that queries the bundle by type or keyword. The selection logic lives in your code, not in the format.
What Agent Skills Actually Does
A Skill is a folder. Inside: a SKILL.md plus any supporting files — scripts, templates, example outputs, reference documents.
The SKILL.md has two distinct jobs. The description field acts as a semantic trigger — Claude reads it and decides whether this skill applies to the current task. The body contains whatever you want Claude to know or do: procedures, schema documentation, brand guidelines, SQL patterns.
---
name: orders-schema
description: >
Use when the task involves querying, analyzing, or joining the orders table,
including revenue calculations or customer purchase history.
---
Table location: `bigquery://my-project.ecommerce.orders`
Primary key: `order_id`. Join to `customers` on `customer_id`.
For revenue: use `confirmed_at`, not `created_at`.When Claude encounters a task, it reads each available skill’s description and decides whether to load the full content. This happens automatically — no prompt engineering or orchestration code required.
The key architectural difference from OKF: Claude makes the selection, not your code. The trigger logic lives in the model reasoning.
Where Scale Breaks Both Formats
Both formats support knowledge and procedure equally. Both use Markdown plus YAML, belong in version control, and include resource references. The content model is nearly identical, but the consumption model differs:
- OKF: your deterministic orchestration code decides what to fetch, when, and for which agent.
- Skills: the probabilistic model (Claude) decides what to load based on task matching.
At small scale, either works. But suppose you have 150 tables across three data domains. Here’s where things break down in production.
With OKF, 150 tables means 150 files. An agent building a revenue query fetches orders.md and revenue.md. Context usage scales with task scope, not knowledge base size. This is OKF’s biggest advantage. But it creates its own problem: someone has to write the orchestration code that fetches the right files at the right time. That code doesn’t exist in the format.
With Skills, you can’t put 150 schemas in one file. When Claude activates a skill, it loads the entire SKILL.md. One file with 150 schemas means every data-related task loads all 150 schemas into the context window, regardless of which table the task involves. So you split: one skill per domain. This works until you’re loading a full domain when the task only needs one table.
Stacking untyped text into a context window doesn’t make an agent smarter. It makes it distracted. At scale, deterministic fetching will always beat probabilistic guessing.
What’s Missing: Strict Contracts and Determinism
At QuotyAI, we realized early on that an AI agent is only as reliable as its runtime constraints. Both OKF and Skills fail to provide these constraints.
What’s Missing From Skills: Typed Contracts Skills need more than a description field and a Markdown body. They lack what we call typed contracts:
- No type system: A skill documenting a schema looks identical to one defining a multi-step workflow. There’s no
type: knowledgeortype: procedure. - No input/output contracts: A “generate SQL query” skill might assume a table name and output format, but Claude infers it from prose. There’s no structured schema enforcing what goes in and what comes out.
- No failure boundaries: If a skill fails, it fails ambiguously. There’s no defined set of error codes (
SLOT_UNAVAILABLE,CUSTOMER_NOT_FOUND) that a deterministic fallback path can catch.
What’s Missing From OKF: Agent Execution Hooks OKF describes a knowledge graph, but doesn’t give agents an executable map through it.
- Concepts are passive: An
orderstable concept doesn’t tell the agent to “fetchrevenue.mdbefore writing any query.” The agent receives a concept and probabilistically decides what to do next. There are no agent execution hooks. - No design-time vs runtime separation: OKF files are a design-time artifact, but agents need runtime reasoning. A file doesn’t provide a deterministic test runner or an interpreter to validate if the agent actually understood the concept.
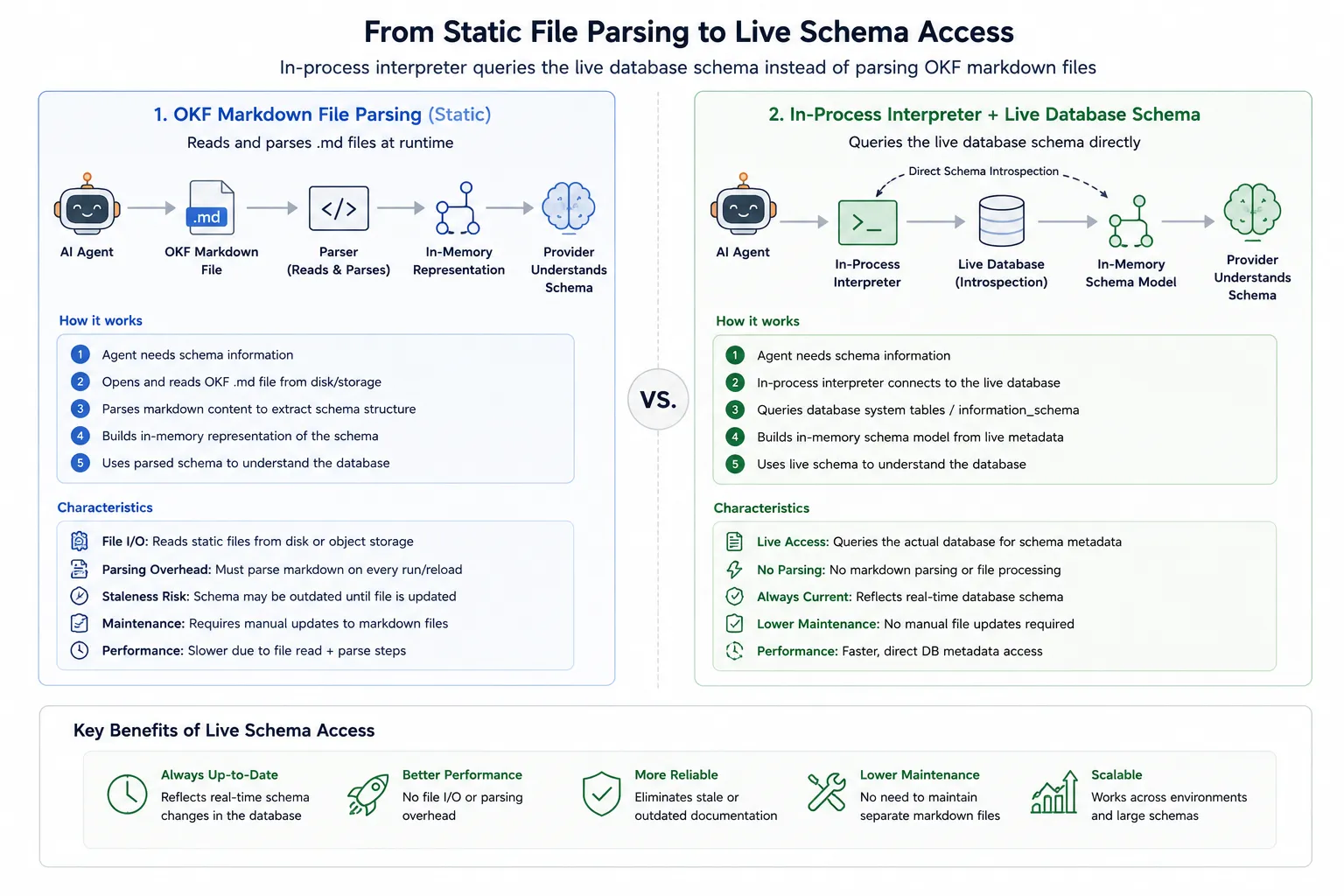
A Third Path That Beats Both: Determinism as Infrastructure
There’s a stronger argument than “fix OKF, fix Skills.” It’s this: pre-authored static knowledge files are the wrong unit altogether.
The 2023 RAG wave relied on “better lookup” of static files. The next wave of agents is built on deterministic execution layers. The more promising direction is an agent equipped with an in-process interpreter (like QuickJS) that computes what it needs at runtime instead of reading what a human wrote in advance.
When we introduced an in-process interpreter at QuotyAI, we moved agent latency from ~2.5s average to a fixed 24ms for routing decisions. Why? Because conditional logic and state management came out of the LLM and into deterministic code.
The goal isn’t to make the model never wrong — it’s to catch errors fast and recover deterministically instead of letting them propagate silently.
The same logic applies to knowledge. A deep agent doesn’t need a pre-written orders.md file. It writes a deterministic tool call against an information_schema, gets the live schema back, filters it in a sandbox, and hands the model three relevant columns instead of three hundred. No human had to author that file. No file can go stale.
Why this computed knowledge access beats static OKF/Skills files:
- No staleness. An OKF concept is a snapshot someone wrote down. A live query is the current state. The
orderstable can add a column tomorrow; a deep agent querying the schema directly knows immediately. - “Done” is a schema, not a feeling. With rubric-based evaluation and typed contracts, an agent doesn’t just read a skill and guess. It executes code, and if a criterion fails, a deterministic grader injects targeted feedback.
- Lower token cost, higher precision. OKF’s per-concept files beat Skills’ all-or-nothing loading. But a computed answer beats both. The agent doesn’t load a 200-word Markdown description and reason about it — it runs
DESCRIBE orders, gets exact column names, and moves on.
The teams shipping reliable agents aren’t the ones with the biggest model bills. They’re the ones whose AI tooling and contracts you can read like a database schema.
When to Use Each Today
Despite their gaps, both formats are usable now — if you pick the right scope.
Use OKF when:
- You have business definitions, tribal knowledge, and the “why” behind a metric that isn’t sitting in a database waiting to be queried.
- Multiple teams need to consume the same typed knowledge without rebuilding it.
Use Skills when:
- Claude is your primary agent runtime.
- You have small, focused workflows that need automatic trigger-based activation without writing custom orchestration logic.
Use Deterministic Code Execution for everything else:
- For everything that is mechanical — “what does the live system look like right now?” — use an in-process interpreter or an MCP connection. Query the truth at runtime instead of reading a static file about it.
This stack uses each piece for what it’s good at. But the actual lesson here is bigger than picking a winner between OKF and Skills. The best agent architecture isn’t about giving models better static markdown files to read. It’s about recognizing that most “knowledge format problems” are really just missing infrastructure.
Build the deterministic runtime underneath the model, and the knowledge problem solves itself.
Frequently Asked Questions
Why do OKF and Agent Skills fail at scale? At scale, OKF requires manual orchestration code to fetch files, while Agent Skills forces models to load massive, all-or-nothing schemas into the context window, degrading reasoning precision. Both are static bottlenecks.
What is a typed skill contract? A typed skill contract is a strict schema defining the inputs, outputs, and exact error boundaries of an agent’s capability, moving it from a probabilistic guess to deterministic code execution.
How does an in-process interpreter improve agents? An in-process interpreter allows an agent to execute live queries and code within its sandbox. Instead of parsing static documentation, the agent queries the live system — getting the exact current schema rather than a stale approximation.