How to build AI agents in next 6-12 months: determinism, schemas, interpreters, and rubrics
Build reliable AI agents by treating deterministic runtimes as core infrastructure—lessons from production at QuotyAI's voice and chat stack.
The models aren’t the differentiator anymore. The runtime is.
I’ve spent the last year building an agentic AI platform. Voice calls, chatbots, sales agents, workflow automation — systems that run in production, talk to real customers, touch real data. A pattern keeps showing up that I don’t see discussed much, probably because it isn’t flattering to the usual narrative about AI progress.
The most reliable AI systems aren’t the ones with the smartest models. They’re the ones with the most deterministic runtimes underneath them.
This isn’t a hot take. It’s what falls out of every production incident report we’ve written for the last twelve months. Models get smarter. Bills get cheaper. The thing that decides whether the agent ships or rolls back is always one layer below the LLM.
§ 01 — What Coding Agents Proved About the Interpreter Layer
Coding agents didn’t take off because models crossed a capability threshold. LLMs were capable at code generation in 2021. What changed was the runtime underneath — a compiler, a test runner, an interpreter that gives unambiguous feedback on every attempt.
The 2023 RAG wave had no equivalent. Retrieval + generation, no execution step, no correction signal. Every verification burden fell on the human. Coding agents moved that burden to the machine.
“AI doesn’t need to be certain. It needs a fast way to be wrong.”
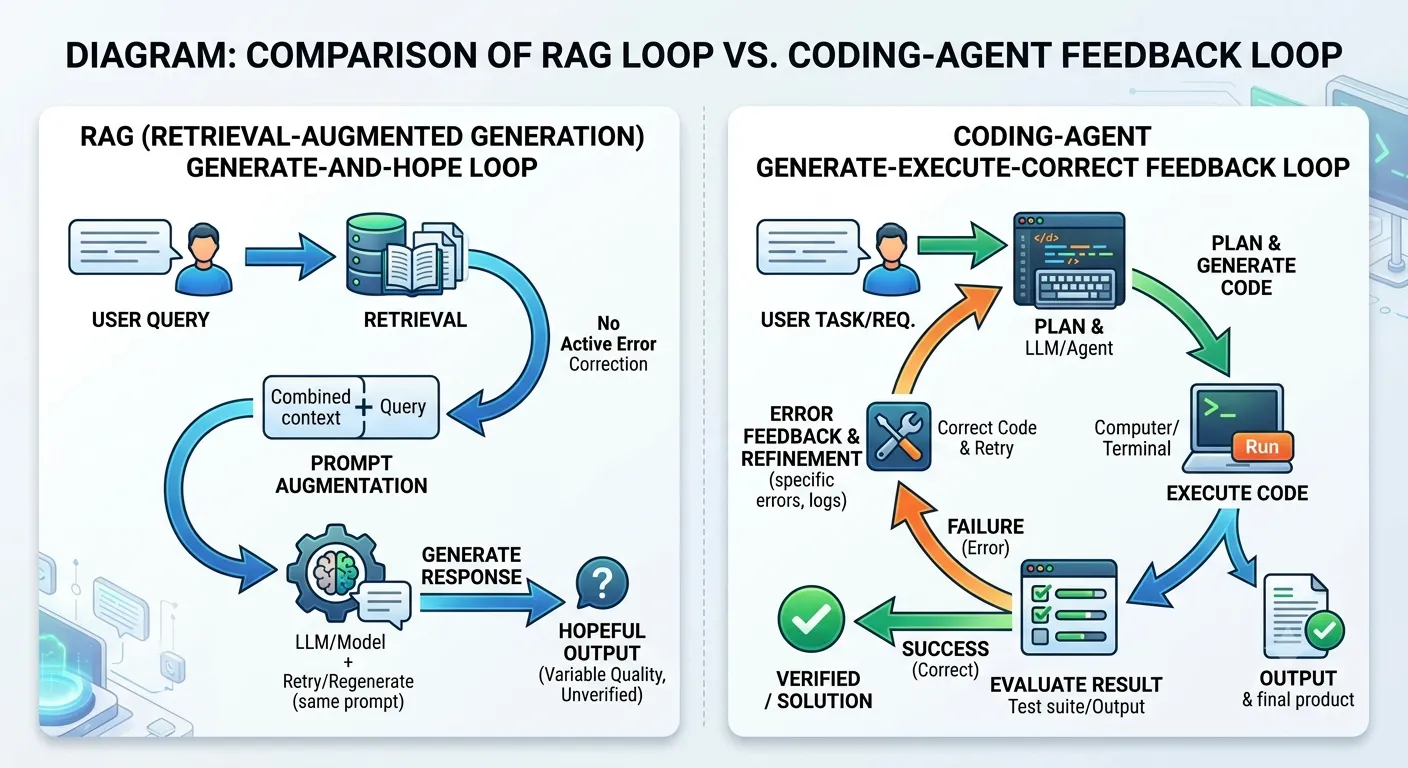
When you put a deterministic execution layer under a probabilistic model, the model’s uncertainty stops being the bottleneck. The runtime handles verification. The model keeps iterating.
This pattern generalises. Wherever you can attach a deterministic execution layer to an LLM, you convert guessing into a feedback loop. Coding was first because the execution layer already existed. The next wave is about building it deliberately for every other domain.
💡 Unique Insight
Coding succeeded first because compilers had a 50-year head start. The next domain doesn’t need a 50-year runtime — it needs any runtime that returns truth in milliseconds. That’s an engineering project, not a research project.
This is the same intuition behind the deterministic bet I made when QuotyAI started: trust the runtime, not the conversation.
§ 02 — The In-Process Interpreter Layer for AI Agents
LangChain’s DeepAgents shipped QuickJS in-process: a JavaScript interpreter inside the agent harness. The AI now reasons through code as a first-class operation — not via round-trips to an external runner.
Tool composition, state management, context filtering, conditional orchestration: all deterministic, all inside the harness.
At QuotyAI, this is what moved our agent latency from ~2.5s average to 24ms fixed on routing decisions. Conditional logic — booking validation, conflict resolution, escalation rules — came out of the LLM and into deterministic code.
| Agent chain | Deterministic runtime | |
|---|---|---|
| Average latency | ~2,500ms | 24ms |
| Variance | high | fixed |
| Debuggability | prompt hunting | stack traces |
| Cost per decision | $0.01–$0.03 | ~$0 |
The LLM handles judgment. The runtime handles facts. The hard part is being honest about which is which — and most teams aren’t, because the LLM looks like it’s handling both.
§ 03 — Rubric-Based Evaluation: How Agents Learn What “Done” Means
Most agents have no concept of task completion. They generate a response and stop. Whether the task is actually finished is left to the caller.
Claude Code introduced /goal — you define a target upfront, the agent works toward it explicitly across iterations. LangChain went further with RubricMiddleware for DeepAgents.
The mechanic: a grader sub-agent (cheaper model, specific tools) evaluates output against a typed rubric before the run concludes. If any criterion fails, the grader injects per-criterion feedback — not “try again”, but exactly which criterion failed and why — and the loop reruns.
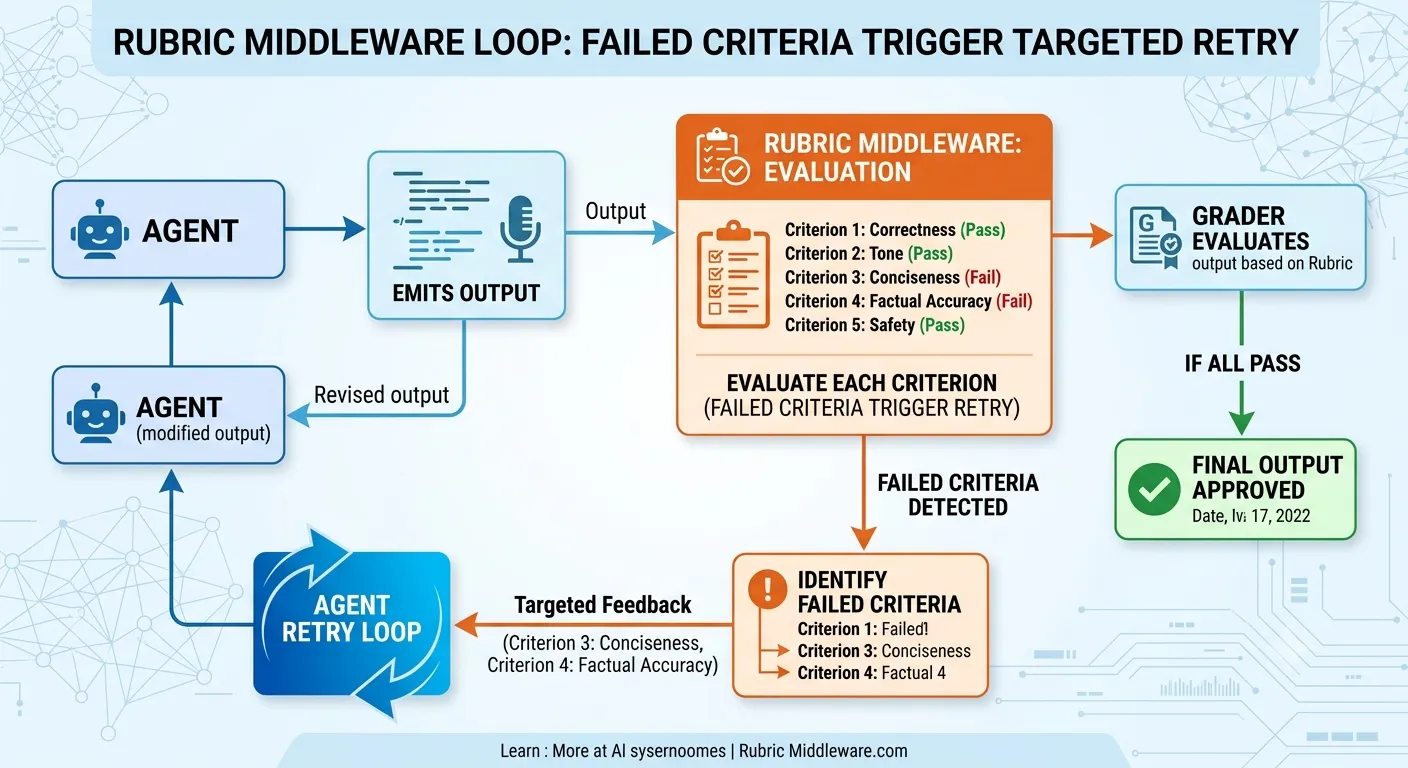
from deepagents import RubricMiddleware, create_deep_agent
rubric = RubricMiddleware(
model="anthropic:claude-haiku-4-5", # grader: fast + cheap
system_prompt="Grade against rubric. Return per-criterion verdicts.",
tools=[run_test_suite, validate_schema], # grader can call tools
max_iterations=5,
)
agent = create_deep_agent(
model="anthropic:claude-sonnet-4-6", # main agent: reasoning
middleware=[rubric],
)
result = agent.invoke({
"messages": [HumanMessage(content="Write find_duplicates(lst)")],
"rubric": (
"- All tests pass in run_test_suite\n"
"- Handles unhashable types (lists, dicts)\n"
"- Returns elements in order of first appearance\n"
),
})Two things worth noting:
- The grader uses a different, cheaper model than the main agent. You’re not paying for Sonnet to check if tests pass — Haiku does it with
run_test_suite. - Feedback is per-criterion, not generic. The agent doesn’t get “try again” — it gets “criterion 3 failed: crashes on unhashable input.”
“Done” is now a schema, not a feeling.
You write the schema once. The grader evaluates deterministically. When iteration 1 fails criterion 3, the agent retargets that criterion specifically.
💡 Unique Insight
When completion becomes a schema, debugging stops being intuition. You don’t ask “did the agent do well?” — you ask “which criterion failed, and on which iteration?” That’s the same question a unit test answers, and unit tests are how every other branch of software engineering escaped the vibes era.
§ 04 — Two-Phase Architecture: Design-Time Contracts vs Runtime Reasoning
Most teams wire up an LLM, give it tools, add a system prompt, and ship. This works for demos. In production, the AI calls the wrong function, returns unexpected shapes, or makes decisions that were supposed to be deterministic.
Root cause: two distinct phases treated as one.
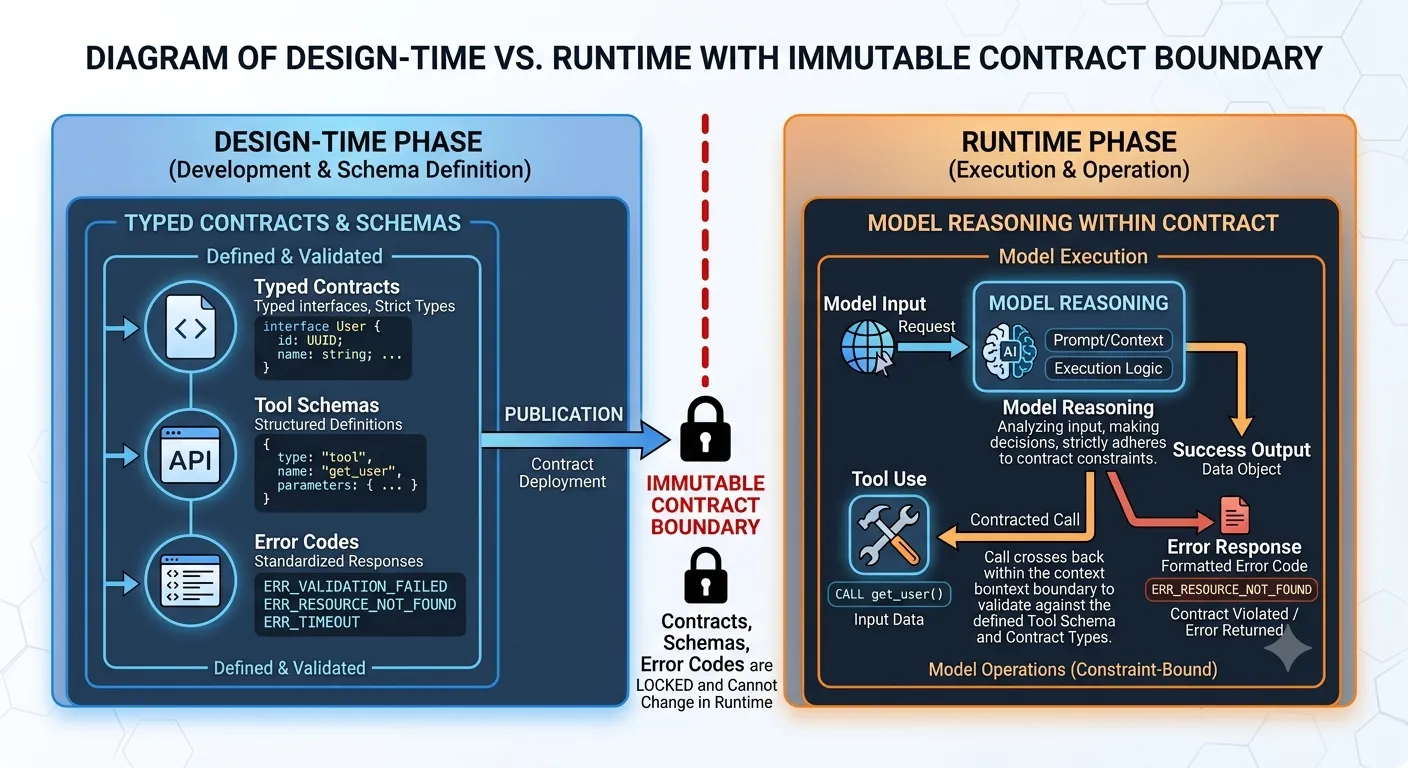
In Phase 1 (design time), a human defines typed inputs and outputs, tool contracts, the allowed error codes, the version. This is checked in, tested, and treated as immutable until you bump the version.
In Phase 2 (runtime), the model reasons within the contract. Output is validated against the schema. Mismatches trigger errors and a deterministic fallback path. Business logic never sees ambiguous data.
The payoff is debuggability. When something breaks: was the contract wrong (Phase 1) or did the model make a bad decision within a correct contract (Phase 2)? Different bugs. Different fixes. Conflating the phases means debugging both at once, which is how you end up with a Slack thread that lasts six days.
At QuotyAI this is the workflow editor: trigger with typed JSON payload → condition block with explicit logic → action with defined output schema. The AI maps customer intent to that structure. It can’t invent new structures. The contract is the boundary.
§ 05 — Typed Contracts vs MCP: Choosing the Right AI Tool Protocol
MCP is a reasonable answer to a real problem — no standard existed for connecting AI to external tools. For third-party tools (Slack, GitHub, Notion) it’s useful.
For first-party application logic, it’s the wrong layer.
MCP standardises tool discovery and invocation. It doesn’t give you typed I/O contracts per tool, versioning, per-domain error schemas, or enforced output shapes.
MCP tool definition:
{
"inputSchema": {
"type": "object",
"properties": {
"data": { "type": "object" }
}
}
}No type enforcement. No error schema. No version. Anything goes in, anything comes out.
Typed skill contract:
{
"name": "create_booking",
"version": "2.1.0",
"input": {
"customer_id": "string:uuid",
"service_id": "string:uuid",
"slot": "datetime:iso8601",
"notes": "string:optional"
},
"output": {
"booking_id": "string:uuid",
"slot_confirmed": "datetime:iso8601"
},
"errors": ["SLOT_UNAVAILABLE", "CUSTOMER_NOT_FOUND", "SERVICE_DISABLED"]
}The execution contract: AI emits structured output → code validates against schema → mismatch triggers error + retry → nothing ambiguous reaches business logic.
MCP will grow for third-party connectivity. Custom contracts will win for first-party logic, because they’re the thing that makes AI output auditable. An auditor doesn’t want to read prompts. They want to read a schema and a log of which schema version returned which output for which input.
§ 06 — Model Routing as Managed Infrastructure
One model for every task is an accounting failure.
| Task | Model | Latency | Cost/call |
|---|---|---|---|
| Intent classification | claude-haiku-4-5 | ~150ms | $0.001 |
| Response generation | claude-sonnet-4-6 | ~1.5s | $0.015 |
| Sensitive PII handling | llama-3-8b (self-hosted) | ~400ms | $0 |
These are not the same constraint. Running Sonnet on every classification call is expensive and slow. Running Haiku on a complex reasoning task gives you wrong answers confidently.
MODEL_ROUTES = {
"intent_classification": {
"model": "claude-haiku-4-5",
"max_tokens": 100,
"latency_budget_ms": 200,
},
"response_generation": {
"model": "claude-sonnet-4-6",
"max_tokens": 1000,
"latency_budget_ms": 2000,
},
"sensitive_data": {
"model": "llama-3-8b", # self-hosted — no data leaves
"max_tokens": 500,
"private": True,
},
}
def call_agent(task_type: str, payload: dict):
config = MODEL_ROUTES[task_type]
return call_model(config["model"], payload, config)This isn’t a user-facing feature. It’s a routing decision before any LLM call. Most teams don’t do this because frameworks don’t enforce it. The latency and cost gaps between tiers are too large to ignore at scale — and the gap widens every model release, because frontier and edge models stop converging in price the moment specialization kicks in.
For the voice channel specifically, this is non-negotiable. A 1.5s response feels natural in chat and broken on a phone call. The routing layer is what lets the same agent serve both.
§ 07 — What Ships on a Deterministic AI Foundation
The 2023 RAG wave built better search. The ceiling was “better lookup.”
What gets built on a deterministic foundation is different in kind — the AI executes, not synthesises.
Schema-first agent frameworks. You’ll define AI contracts the way you currently define database schemas — with validation, versioning, and migration tooling. The schema layer will be a CLI artifact, not a system prompt.
Rubric-based agent CI/CD. Before merging a change to your agent’s tool set or model version, a rubric test suite runs. Green means the agent still satisfies its defined completion criteria. Same pattern as unit tests, applied to agent behavior.
Model routing as a managed layer. Task-type → model selection moves below the application layer entirely, the way DNS sits below HTTP. Your application won’t know which model ran — only that the contract was satisfied.
💡 Unique Insight
The teams shipping reliable agents in 2026 aren’t the ones with the biggest model bills. They’re the ones whose contracts you could read like a database schema. The interesting infrastructure is the one you don’t see in the demo.
The deeper point: the value isn’t in the model. Models improve continuously and the best ones keep getting cheaper. The value is in the runtime that makes model output trustworthy enough to act on — typed contracts, deterministic execution, verifiable completion.
That runtime is being built right now. Mostly quietly. Mostly by people who got burned by the first wave.
Frequently Asked Questions
Q: Why are deterministic runtimes more important than smarter models for AI agents? A: Smarter models still need a way to be wrong fast. A deterministic runtime — a compiler, an interpreter, a validator — gives every guess an unambiguous verdict, so the model iterates instead of hallucinating. The reliability ceiling is set by the runtime, not the parameter count.
Q: How does an in-process interpreter like QuickJS make agents more reliable? A: An in-process interpreter lets the agent reason through code as a first-class operation. Tool composition, state management, and conditional logic become deterministic execution instead of probabilistic generation. At QuotyAI this moved agent latency from ~2.5s to a fixed 24ms for routing decisions.
Q: What is a typed skill contract and how does it differ from MCP? A: A typed skill contract pins down input shape, output shape, version, and the exact set of allowed errors for one tool. MCP standardises tool discovery and invocation but leaves I/O loosely typed. For first-party application logic, typed contracts make AI output auditable; MCP is the right layer for third-party connectors like Slack or GitHub.
I’m building QuotyAI — an agentic AI platform for voice, chat, and business automation. If you’re working on deterministic agent infrastructure, try it free and I’d like to hear what you’re seeing.
References
Found this useful? Share it.
Related articles
Open Knowledge Format (OKF) vs Agent Skills
Open Knowledge Format (OKF) vs Agent Skills. Learn why deterministic execution beats static knowledge files for AI agents.
Read articleThe Deterministic Bet: Why I'm Building QuotyAI to Be Reliable, Not Just Chatty
Most AI agents are fancy receptionists that break when you need real business logic. Here's why I'm betting everything on deterministic code generation instead.
Read articleThe Why Behind QuotyAI
Why I'm building an AI that calculates correctly instead of just sounding smart. A personal story about broken tools and what happens when you refuse to accept 95% accuracy.
Read article